Driver HA
只能在Standalone或者Mesos 模式 下可以用
因为SparkStreaming是7*24小时运行,Driver只是一个简单的进程,有可能挂掉,所以实现Driver的HA就有必要。
如果使用的Client模式就无法实现Driver HA ,这里针对的是cluster模式。
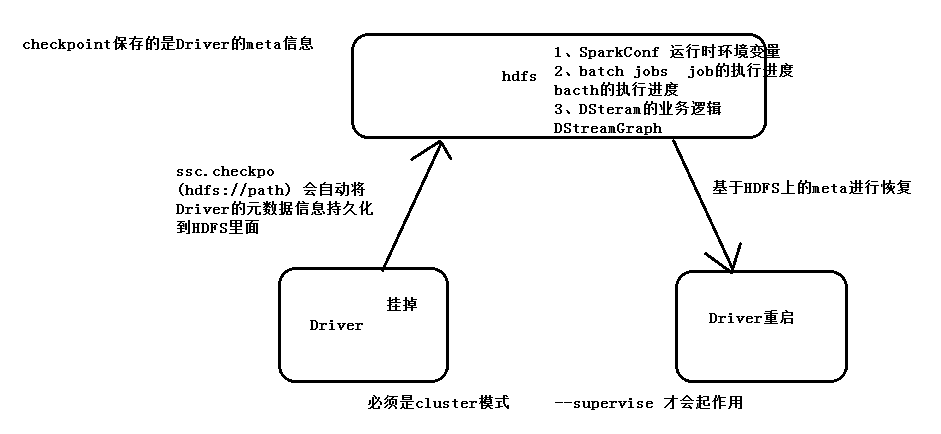
Driver中元数据包括:
1. 创建应用程序的配置信息。
2. Dstream的操作逻辑。
3. job中没有完成的批次数据,也就是job的执行进度。
实现Driver的高可用有两个步骤:
第一:提交任务层面,在提交任务的时候加上选项 –supervise,当Driver挂掉的时候会自动重启Driver。
第二:代码层面,使用JavaStreamingContext.getOrCreate(checkpoint路径,JavaStreamingContextFactory)
此checkpoint路径路径下无driver信息则新建,有则根据信息恢复JavaStreamingContext
代码:
/**
*
* Spark standalone or Mesos with cluster deploy mode only:
* 在提交application的时候 添加 --supervise 选项 如果Driver挂掉 会自动启动一个Driver
* SparkStreaming
* @author Jeffrey.deng
*
*/
public class SparkStreamingOnHDFS {
public static void main(String[] args) {
final SparkConf conf = new SparkConf().setMaster("local[1]").setAppName("SparkStreamingOnHDFS");
final String checkpointDirectory = "hdfs://hadoop1:9000/library/SparkStreaming/CheckPoint_20170523";
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() {
@Override
public JavaStreamingContext create() {
return createContext(checkpointDirectory,conf);
}
};
// 通过factory来创建JavaStreamingContext
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate(checkpointDirectory, factory); // 此路径下无driver信息则新建,有则根据信息恢复
jsc.start();
jsc.awaitTermination();
// jsc.close();
}
@SuppressWarnings("deprecation")
private static JavaStreamingContext createContext(String checkpointDirectory,SparkConf conf) {
// If you do not see this printed,
// that means the StreamingContext has been loaded from the new checkpoint
System.out.println("Creating new context");
SparkConf sparkConf = conf;
// Create the context with a 1 second batch size
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(15));
// 指定路径 会先恢复Driver需要的信息写到此路径下
ssc.checkpoint(checkpointDirectory);
/**
* 只是监控文件夹下新增的文件,减少的文件是监控不到的 文件内容有改动也是监控不到
*/
JavaDStream<String> lines = ssc.textFileStream("hdfs://hadoop1:9000/hdfs/");
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" "));
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
counts.print();
return ssc;
}
}第一次启动程序成功后,会输出
System.out.println("Creating new context");
第二次启动则 不会输出,应该JavaStreamingContext 是根据checkpoint文件夹下的 信息恢复 的。
要重新从开始计算数据的话,那就要把checkpoint路径下的信息删除,才行