SparkStreaming是流式处理框架
是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理.
实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ, Kinesis, 或者TCP sockets,
并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。
最终,处理后的数据可以存放在文件系统,数据库,以及实时展现。
SparkStreaming与Storm的区别
Storm是 纯实时 的流式处理框架,SparkSteaming是准实时的流式处理框架(微批处理)
因为微批处理,SparkStreaming的吞吐量比Storm要高
Storm对于事务支持 要比SparkStreaming要好
对于流式处理框架,事务就是数据恰好处理一次,
对于对数据安全要求的如银行,选用storm
Storm支持 动态的资源调度,SparkSteaming不支持
即动态对节点性能调整,高峰时加强,低峰时降低
SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理
Storm适合简单的汇总型计算,SparkStreaming适合复杂的数据处理
SparkStreaming中可以使用sql语句来处理数据,Storm无法实现
SparkStreaming初始理解
原理是讲输入数据以时间片(秒级)为单位划分,然后以类似批处理方式处理每个分片的数据
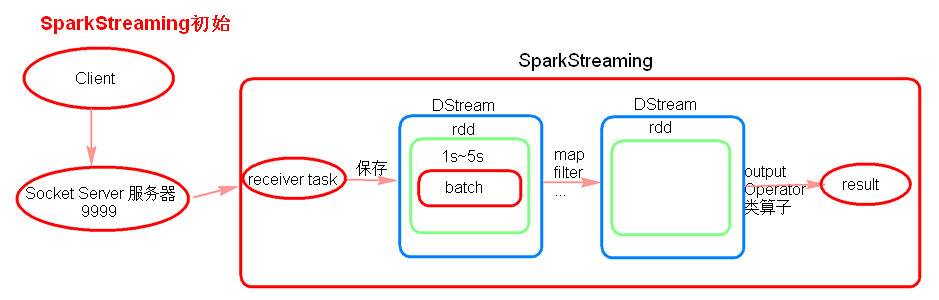
注意:
receiver task 是7*24小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到 batch 中。假设 batch Interval 为5s,那么会将接收来的数据每隔5秒封装到一个batch中
例如:假设 batchInterval为5秒,每隔5秒通过SparkStreamin将得到一个RDD,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第6~9秒一边在接收数据,一边在计算任务,9~10秒只是在接收数据。然后在第11秒的时候重复上面的操作。
因为batch是没有分布式计算的特性,所以将数据封装到 RDD 中,最终封装到 Dstream 中。
每一个batch对应一个RDD
一系列连续的RDD组成DStream
对DStream的操作会转成对底层RDD的操作
receiver task 默认持久化级别为 MEMORY_AND_DISK_SER_2 , receiver task 会将数据位置报告个 Driver 中的 receiverTracker
如果 job执行的时间大于batchInterval 会有什么样的问题?
接收来的数据会 越堆积越多 ,最后可能会导致 OOM。
public class WordCountOnline {
@SuppressWarnings("deprecation")
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline");
/**
* 在创建streaminContext的时候 设置batch Interval为5s
*/
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
// nc -lk 9999
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("hadoop1", 9999);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" "));
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
//outputoperator类的算子
counts.print();
jsc.start();
jsc.awaitTermination(); // 阻塞等待数据输入
jsc.stop(true); // stopSparkContext : Stop the associated SparkContext or not 默认ture
}
} 创建StreamingContext 对象,从数据源得到 DStream对象,对对象执行算子操作,以一个outputOperator类算子触发Job
SparkStreaming中分为有状态的算子和无状态的算子
在上面的 WordCount例子中累加算子用的是 reduceByKey 是无状态的算子,SparkStreaming中是以一个batch的数据执行计算的,也就是内部把一个batch的数据封装成一个RDD,对这个RDD执行算子操作,也就是说 reduceByKey 计算的是一个 batch 的count值,等到第二个batch又归零了。那这时就需要用到有状态的算子,把上一个batch的计算结果拿过来。
public class UpdateStateByKeyOperator {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("UpdateStateByKeyDemo");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
/**
* 多久会将内存中的数据(每一个key所对应的状态)写入到磁盘上一份呢?
* 如果你的batch interval小于10s 那么10s会将内存中的数据写入到磁盘一份
* 如果bacth interval 大于10s,那么就以bacth interval为准
*/
jsc.checkpoint("hdfs://node01:8020/sscheckpoint01");
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("hadoop1", 8888);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" "));
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairDStream<String, Integer> counts = ones.updateStateByKey(new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() {
@Override
public Optional<Integer> call(List<Integer> values, Optional<Integer> state) throws Exception {
/**
* values:经过分组最后 这个key所对应的value [1,1,1,1,1]
* state:这个key在本次之前之前的状态,上一个batch的计算结果
*/
Integer updateValue = 0 ;
if(state.isPresent()){
updateValue = state.get();
}
for (Integer value : values) {
updateValue += value;
}
return Optional.of(updateValue);
}
});
//output operator
counts.print();
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}窗口操作算子
窗口操作即对一个时间段内的数据执行计算,不是全部时间
那通过调整 bacth interval 大小也能计算一段时间的,为什么还需要窗口算子呢?
当每个窗口时间需要计算几个batch的数据量,这样就不行了
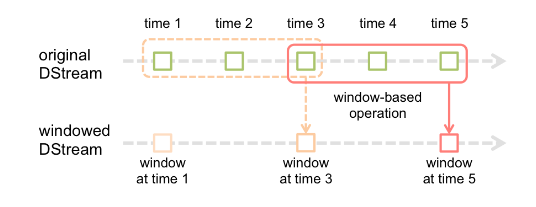
假设每隔5s 1个batch,上图中窗口长度为15s,窗口滑动间隔10s。 time3时刻重复计算
窗口长度和滑动间隔 必须是 batchInterval的整数倍。如果不是整数倍会检测报错。
reduceByKeyAndWindow
每隔10秒,计算最近60秒内的数据,那么这个窗口大小就是60秒,里面有12个rdd,在没有计算之前,这些rdd是不会进行计算的。那么在计算的时候会将这12个rdd聚合 起来,然后一起执行reduceByKeyAndWindow
reduceByKeyAndWindow是 针对窗口操作 的而不是针对batch操作的。
参数
/**
* Return a new DStream by applying `reduceByKey` over a sliding window. This is similar to
* `DStream.reduceByKey()` but applies it over a sliding window. Hash partitioning is used to
* generate the RDDs with Spark's default number of partitions.
* @param reduceFunc associative reduce function
* @param windowDuration width of the window; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., the interval after which
* the new DStream will generate RDDs); must be a multiple of this
* DStream's batching interval
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration, //窗口大小
slideDuration: Duration // 每次窗口移动大小
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(reduceFunc, windowDuration, slideDuration, defaultPartitioner())
}例子
public class WindowOperator {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WindowHotWord");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
jssc.checkpoint("hdfs://192.168.126.111:8020/sscheckpoint02");
JavaReceiverInputDStream<String> searchLogsDStream = jssc.socketTextStream("hadoop1", 9999);
//word 1
JavaDStream<String> searchWordsDStream = searchLogsDStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
}
});
// 将搜索词映射为(searchWord, 1)的tuple格式
JavaPairDStream<String, Integer> searchWordPairDStream = searchWordsDStream.mapToPair(
new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String searchWord)
throws Exception {
return new Tuple2<String, Integer>(searchWord, 1);
}
});
/**
* 每隔10秒,计算最近60秒内的数据,那么这个窗口大小就是60秒,里面有12个rdd,在没有计算之前,这些rdd是不会进行计算的。那么在计算的时候会将这12个rdd聚合起来,然后一起执行reduceByKeyAndWindow
* 操作 ,reduceByKeyAndWindow是针对窗口操作的而不是针对DStream操作的。
*/
JavaPairDStream<String, Integer> searchWordCountsDStream =
searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}, Durations.seconds(60), Durations.seconds(10)); //指定窗口大小为1分钟,窗口移动间隔为10秒
searchWordCountsDStream.print();
jssc.start();
jssc.awaitTermination();
jssc.close();
}
}优化后的window窗口操作
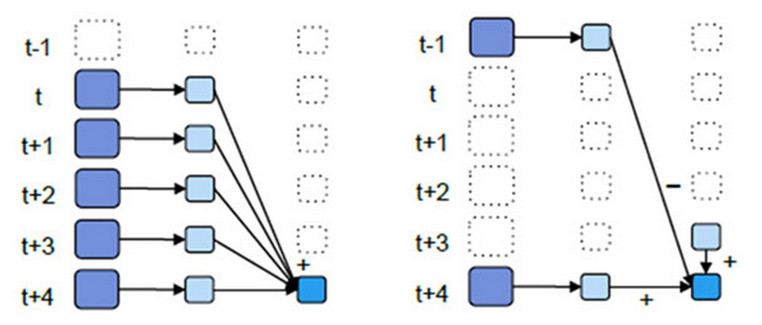
图中左边为未优化,右边为优化
左边窗口大小为5秒,窗口间隔为1秒,也就是说每移动一个间隔,就要计算五个RDD,也就是一个RDD会被重复就算5次
右的话,每移动一个间隔,也就是会增加 t+4 时刻的RDD,同时去掉 t-1 时刻的RDD,其余4个RDD就不需要重复计算了
也就是在t+3窗口的基础,只需要计算一次 t+4 时刻 ,与之相加,计算一次 t-1 时刻的,与之相减
优化后的window操作要保存状态所以要设置checkpoint路径,没有优化的window操作可以不设置checkpoint路径。
参数:
/**
* Return a new DStream by applying incremental `reduceByKey` over a sliding window.
* The reduced value of over a new window is calculated using the old window's reduced value :
* 1. reduce the new values that entered the window (e.g., adding new counts)
*
* 2. "inverse reduce" the old values that left the window (e.g., subtracting old counts)
*
* This is more efficient than reduceByKeyAndWindow without "inverse reduce" function.
* However, it is applicable to only "invertible reduce functions".
* Hash partitioning is used to generate the RDDs with Spark's default number of partitions.
* @param reduceFunc associative reduce function
* @param invReduceFunc inverse reduce function
* @param windowDuration width of the window; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., the interval after which
* the new DStream will generate RDDs); must be a multiple of this
* DStream's batching interval
* @param filterFunc Optional function to filter expired key-value pairs;
* only pairs that satisfy the function are retained
*/
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V, // 一个rdd内聚合的方法
invReduceFunc: (V, V) => V, // 最前一个rdd的减去方法
windowDuration: Duration,
slideDuration: Duration = self.slideDuration,
numPartitions: Int = ssc.sc.defaultParallelism,
filterFunc: ((K, V)) => Boolean = null
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(
reduceFunc, invReduceFunc, windowDuration,
slideDuration, defaultPartitioner(numPartitions), filterFunc
)
}上一个例子的优化版
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
jssc.checkpoint("hdfs://192.168.126.111:9000/sscheckpoint02");JavaPairDStream<String, Integer> searchWordCountsDStream = searchWordPairDStream.reduceByKeyAndWindow(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
},new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 - v2;
}
}, Durations.seconds(60), Durations.seconds(10));
上面的算子全是针对DStream操作的,那如果将DStream转成RDD操作呢
前面讲了,SparkStreaming是一个batch Interval时间的数据作为一个单位做处理,每一个 batch 封装成一个RDD,所以一个DStream底层即由很多个RDD组成,只是只需讲这些 RDD 遍历出来,就可以执行熟悉的RDD算子了。
foreachRDD
得到DStream封装的RDDs
outputOperator算子,即无返回结果
使用foreachRDD这个算子,必须对 抽取出来的RDD执行action类算子的触发 , 才会执行
例如: 利用foreachRDD的得到每一个RDD,再对每个RDD执行foreachPartition写数据库
/**
* 使用foreachRDD这个算子,必须对抽取出来的RDD执行action类算子的触发
*/
countsDStream.foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() {
@Override
public void call(JavaPairRDD<String, Integer> pairRdd) throws Exception {
pairRdd.foreachPartition(new VoidFunction<Iterator<Tuple2<String,Integer>>>() {
@Override
public void call(Iterator<Tuple2<String, Integer>> vs) throws Exception {
JDBCWrapper jdbcWrapper = JDBCWrapper.getJDBCInstance();
List<Object[]> insertParams = new ArrayList<Object[]>();
while(vs.hasNext()){
Tuple2<String, Integer> next = vs.next();
insertParams.add(new Object[]{next._1,next._2});
}
System.out.println(insertParams);
jdbcWrapper.doBatch("INSERT INTO wordcount VALUES(?,?)", insertParams);
}
});
}
});注意点:
foreachRDD里出现了rdd,而我们认知中对rdd的操作是在Driver端,所以foreachRDD里的代码是在Driver中执行的,只有rdd.foreachPartition里面的代码才是executor里执行的,所以不能在foreachRDD里创建数据库连接,而是要在rdd.foreachPartition里 。
利用foreachRDD我们可以在SparkStreaming里动态的改变广播变量,因为foreachRDD里面的代码是在Driver端执行的,可以由RDD获取到SparkContext然后改变广播变量
transform
同 foreachRDD
但是为 transformation类算子 , 返回 DSream
可以通过transform算子,对DStream做RDD到RDD的任意操作。
/**
* 过滤黑名单
*/
public class TransformOperator {
@SuppressWarnings("deprecation")
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("TransformBlacklist");
final JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
// 先做一份模拟的黑名单RDD
List<Tuple2<String, Boolean>> blacklist = new ArrayList<Tuple2<String, Boolean>>();
blacklist.add(new Tuple2<String, Boolean>("tom", true));
final JavaPairRDD<String, Boolean> blacklistRDD = jssc.sparkContext().parallelizePairs(blacklist);
// 这里的日志格式,就简化一下,就是date username的方式
JavaReceiverInputDStream<String> adsClickLogDStream = jssc.socketTextStream("hadoop1", 8888);
JavaPairDStream<String, String> userAdsClickLogDStream = adsClickLogDStream.mapToPair(
new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String adsClickLog) throws Exception {
return new Tuple2<String, String>(adsClickLog.split(" ")[1], adsClickLog);
}
});
JavaDStream<String> validAdsClickLogDStream = userAdsClickLogDStream.transform(new Function<JavaPairRDD<String, String>, JavaRDD<String>>() {
@Override
public JavaRDD<String> call(JavaPairRDD<String, String> userAdsClickLogRDD) throws Exception {
JavaPairRDD<String, Tuple2<String, Optional<Boolean>>> joined = userAdsClickLogRDD.leftOuterJoin(blacklistRDD);
JavaPairRDD<String, Tuple2<String, Optional<Boolean>>> filtered = joined.filter(new Function<Tuple2<String,Tuple2<String,Optional<Boolean>>>, Boolean>() {
@Override
public Boolean call(Tuple2<String, Tuple2<String, Optional<Boolean>>> tuple) throws Exception {
Optional<Boolean> option = tuple._2._2;
if(option.isPresent()){
return !option.get();
}
return true;
}
});
return filtered.map(new Function<Tuple2<String,Tuple2<String,Optional<Boolean>>>, String>() {
@Override
public String call(Tuple2<String, Tuple2<String, Optional<Boolean>>> tuple) throws Exception {
return tuple._2._1;
}
});
}
});
//outputOperator
validAdsClickLogDStream.print();
jssc.start();
jssc.awaitTermination();
jssc.close();
}
}