Spark MLlib — 机器学习库
Spark MLlib (Machine Learning Library )
Spark调优 — 数据倾斜解决方案
使用Hive ETL预处理数据
过滤少数导致倾斜的key – 提高shuffle操作的并行度
加随机前缀进行双重聚合
将reduce join转为map join
采样分拆RDD加随机前缀和扩容RDD进行 Join
全部Key使用随机前缀和扩容RDD进行 join
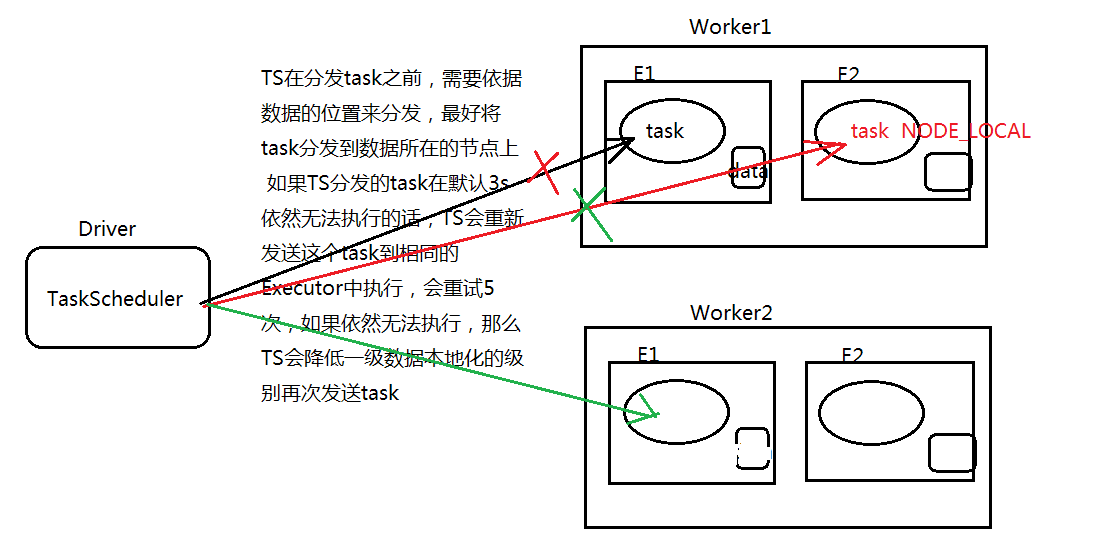
Spark调优 — 数据本地性
Spark调优
资源调优
任务的并行度调优
代码调优
Shuffle调优
调节堆外内存
解决问题
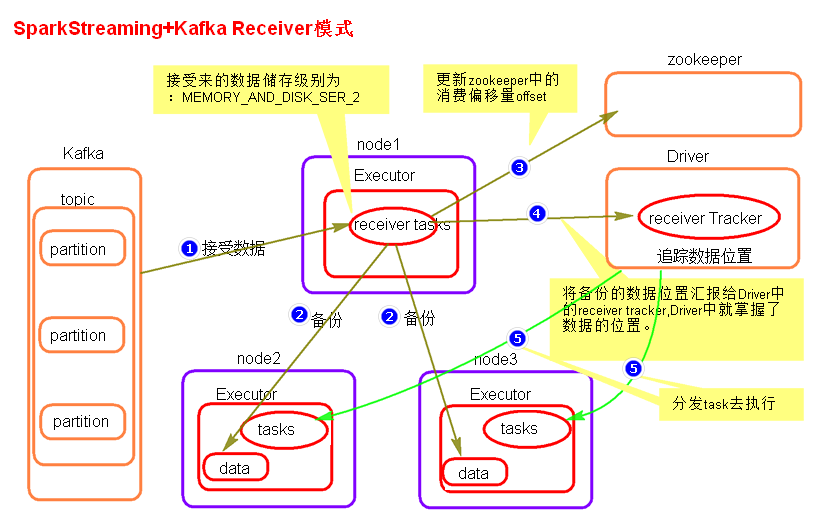
SparkStreaming 与 Kafka 整合