SparkStreaming不断的接受数据,但是会有高峰与低峰,高峰时数据量大的,低峰时数据量小,这样 batch interval 不好设置。
但是可以通过中间件(像 flume、Kafka)来对数据做一个缓冲,让数据先写到中间件中,再从中间件中读取到SparkStreaming中,
这样数据的输入速度就比较平滑,适合流失处理
这里采用 Kafka 作为中间件,SparkStreaming 与 Kafka 整合方式有两种:Receiver 与 Direct
Receiver 模式
使用Kafka高阶API来在Zookeeper中保存消费过的偏移量
receiver模式原理图
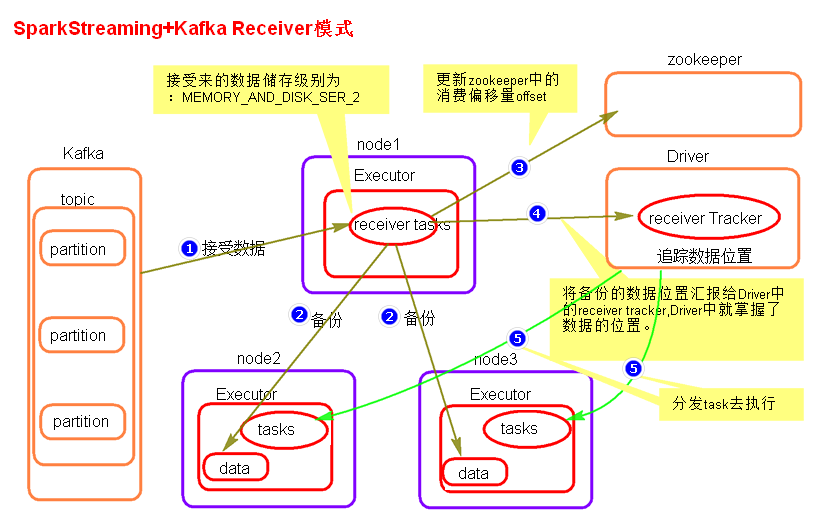
SparkStreaming程序启动起来后,会创建一个Job,会 Receiver Tasks 分发到Executor中执行,Receiver Tasks会接收Kafka的数据,
数据会被 持久化,默认级别为 MEMORY_AND_DISK_SER_2,这个级别可以修改
receiver task对接收过来的数据进行分发备份,分发到不同的节点
每隔 spark.streaming.blockInterval 时间生成 一个文件,分发一次 ; 每隔 batchInterval 时间,标记为 一个Batch(RDD)
不同的文件分发到不同的节点,所以每个文件相当于这个batch的 一个block
这个batch的文件分发完成后, receiver task会去 Zookeeper 中更新消费偏移量。
然后向 Driver 中的 ReceiverTracker 汇报block文件位置。
然后 Driver 中的 TAGScheduler 会根据 文件位置 按照 数据本地化级别 将 Task 分发到这些节点处理这个 batch 的数据
receiver模式中存在的问题
当 Driver 进程挂掉之后,Driver分配的 Executor都会被杀死 , 当更新完Zookeeper偏移量后,还未消费,Driver如果挂掉了,那就会一部分数据没有消费。第二:Driver如果挂掉了就会存在找不到数据的问题,相当于丢失数据。
如何解决这个问题?
开启 WAL(write ahead log)预写日志机制
在接受过来数据备份到其他节点的时候,同时 备份到HDFS 上一份(我们可以将将接收来的数据的持久化级别降级到MEMORY_AND_DISK),这样就能保证数据的安全性。
不过,因为写HDFS比较消耗性能,要在备份完数据之后才能进行更新zookeeper以及汇报位置等,这样会增加job的执行时间,这样对于任务的执行提高了延迟度。
开启方法:
spark.streaming.receiver.writeAheadLog.enable 设置为 true
同时指定保存位置 : sc.checkpoint( path )
receiver的并行度设置
receiver的并行度是由 spark.streaming.blockInterval 来决定的,默认 200ms,
假设: batchInterval 为5s, 那么每隔 blockInterval 就会产生一个block,每隔 batchInterval 产生一个 Batch(RDD)。
这里每个 block 就对应 Batch(RDD)的 Partition,这样每 batchInterval 秒产生的这个RDD的 partition 为 25 个,并行度就是25。
即 并行度(Partition个数) = batchInterval / blockInterval
如果想提高并行度可以减少 blockInterval 的数值,但是最好不要低于50ms。太小会使一个block数据量过少。或者增大 batchInterval 的数值
整合方法:
通过 KafkaUtils.createStream() 方法创建 JavaPairReceiverInputDStream 对象
JavaPairReceiverInputDStream 为 KV格式 RDD,k:offset v:values
引入包 spark-streaming-kafka_2.10-1.6.0.jar 1.6.0为Spark版本
/**
* Create an input stream that pulls messages from Kafka Brokers.
* @param jssc JavaStreamingContext object
* @param zkQuorum Zookeeper quorum (hostname:port,hostname:port,..).
* @param groupId The group id for this consumer.
* @param topics Map of (topic_name -> numPartitions) to consume. Each partition is consumed
* in its own thread.
* @param storageLevel RDD storage level.
* @return DStream of (Kafka message key, Kafka message value)
*/
def createStream(
jssc: JavaStreamingContext, // StreamingContext
zkQuorum: String, // ZooKeeper集群信息(接受Kafka数据的时候会从Zookeeper中获得Offset等元数据信息)
groupId: String, // Consumer Group
topics: JMap[String, JInt], // Map集合 {消费的Topic:并发读取Topic中Partition的线程数,...}
storageLevel: StorageLevel // 对接收的数据持久化级别
): JavaPairReceiverInputDStream[String, String] = {
createStream(jssc.ssc, zkQuorum, groupId, Map(topics.asScala.mapValues(_.intValue()).toSeq: _*),
storageLevel)
}代码:
public class SparkStreamingOnKafkaReceiver {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("SparkStreamingOnKafkaReceiver")
.setMaster("local[2]")
.set("spark.streaming.receiver.writeAheadLog.enable", "true");
// .set("spark.streaming.concurrentJobs", "10");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
// writeAheadLog 日志存储位置
jsc.checkpoint("d://receivedata");
//JavaReceiverInputDStream lines = FlumeUtils.createStream(jsc,"192.168.5.1", 9999);
//JavaReceiverInputDStream lines = FlumeUtils.createPollingStream(jsc, "192.168.5.128", 8899);
/**
* 1、KafkaUtils.createStream 使用五个参数的方法,设置receiver的存储级别
* 2、在java里面使用多个receiver,需要将JavaPairReceiverInputDStream转换成javaDstream使用toJavaDstream
* val numStreams = 5
* val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
* val unifiedStream = streamingContext.union(kafkaStreams)
*/
Map<String, Integer> topicConsumerConcurrency = new HashMap<String, Integer>();
// Map of (topic_name -> numPartitions) to consume. Each partition is consumed in its own thread.
// 并发读取Topic中Partition的线程数
topicConsumerConcurrency.put("Abgelababy", 1);
//第一个参数是StreamingContext
//第二个参数是ZooKeeper集群信息(接受Kafka数据的时候会从Zookeeper中获得Offset等元数据信息)
//第三个参数是Consumer Group
//第四个参数是Map集合 {消费的Topic:并发读取Topic中Partition的线程数,...}
//第五个参数是持久化级别 如果开启了预写日志,那么memrory_and_disk_2 就不需要_2了
JavaPairReceiverInputDStream<String, String> lines = KafkaUtils.createStream(jsc,
"192.168.126.111:2181,192.168.126.112:2181,192.168.126.113:2181", "MyFiestConsumerGroup", topicConsumerConcurrency, StorageLevel.MEMORY_ONLY());
/**
*
* lines是一个kv格式的 k:offset v:values
*/
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String, String>, String>() {
@Override
public Iterable<String> call(Tuple2<String, String> tuple) throws Exception {
return Arrays.asList(tuple._2.split("\t"));
}
});
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { //对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce)
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordsCount.print();
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
Driect 模式
直接操作Kafka底层的源数据信息
Driect模式就是将kafka看成 Spark Streaming的底层文件系统,不是被动接收数据,而是主动去取数据。
Driect模式也就是没有 receiver task接收数据。
消费者偏移量也不是用zookeeper来管理,而是 SparkStreaming自己管理 ,默认保存到内存中
如果设置了checkpoint,会将之保存到checkpoint目录,当然也可以实现用zookeeper来管理。
并行度
底层直接读取数据,所以 RDD 的 partition 与 Kafka topic 的partition 对应
所以并行度与 topic 的partition个数 有关
整合方法:
通过 KafkaUtils.createStream() ,传入 broker地址 创建
/**
* Create an input stream that directly pulls messages from Kafka Brokers
* without using any receiver. This stream can guarantee that each message
* from Kafka is included in transformations exactly once (see points below).
*
* Points to note:
* - No receivers: This stream does not use any receiver. It directly queries Kafka
* - Offsets: This does not use Zookeeper to store offsets. The consumed offsets are tracked
* by the stream itself. For interoperability with Kafka monitoring tools that depend on
* Zookeeper, you have to update Kafka/Zookeeper yourself from the streaming application.
* You can access the offsets used in each batch from the generated RDDs (see
* [[org.apache.spark.streaming.kafka.HasOffsetRanges]]).
* - Failure Recovery: To recover from driver failures, you have to enable checkpointing
* in the [[StreamingContext]]. The information on consumed offset can be
* recovered from the checkpoint. See the programming guide for details (constraints, etc.).
* - End-to-end semantics: This stream ensures that every records is effectively received and
* transformed exactly once, but gives no guarantees on whether the transformed data are
* outputted exactly once. For end-to-end exactly-once semantics, you have to either ensure
* that the output operation is idempotent, or use transactions to output records atomically.
* See the programming guide for more details.
*
* @param jssc JavaStreamingContext object
* @param keyClass Class of the keys in the Kafka records
* @param valueClass Class of the values in the Kafka records
* @param keyDecoderClass Class of the key decoder
* @param valueDecoderClass Class type of the value decoder
* @param kafkaParams Kafka <a href="http://kafka.apache.org/documentation.html#configuration">
* configuration parameters</a>. Requires "metadata.broker.list" or "bootstrap.servers"
* to be set with Kafka broker(s) (NOT zookeeper servers), specified in
* host1:port1,host2:port2 form.
* If not starting from a checkpoint, "auto.offset.reset" may be set to "largest" or "smallest"
* to determine where the stream starts (defaults to "largest")
* @param topics Names of the topics to consume
* @tparam K type of Kafka message key
* @tparam V type of Kafka message value
* @tparam KD type of Kafka message key decoder
* @tparam VD type of Kafka message value decoder
* @return DStream of (Kafka message key, Kafka message value)
*/
def createDirectStream[K, V, KD <: Decoder[K], VD <: Decoder[V]](
jssc: JavaStreamingContext, // context
keyClass: Class[K], // key类型 偏移量 可为String
valueClass: Class[V], // 值类型
keyDecoderClass: Class[KD], // key解码器
valueDecoderClass: Class[VD], //值解码器
kafkaParams: JMap[String, String], // 参数 {"meta.broker.list":"地址"}
topics: JSet[String] // topic set集合
): JavaPairInputDStream[K, V] = {
implicit val keyCmt: ClassTag[K] = ClassTag(keyClass)
implicit val valueCmt: ClassTag[V] = ClassTag(valueClass)
implicit val keyDecoderCmt: ClassTag[KD] = ClassTag(keyDecoderClass)
implicit val valueDecoderCmt: ClassTag[VD] = ClassTag(valueDecoderClass)
createDirectStream[K, V, KD, VD](
jssc.ssc,
Map(kafkaParams.asScala.toSeq: _*),
Set(topics.asScala.toSeq: _*)
)
}例子:
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(10));
Map<String, String> kafkaParameters = new HashMap<String, String>();
// broker 地址
kafkaParameters.put("metadata.broker.list", "192.168.126.111:9092,192.168.126.112:9092,192.168.126.113:9092");
HashSet<String> topics = new HashSet<String>();
// 主题
topics.add("Abgelababy");
JavaPairInputDStream<String,String> lines = KafkaUtils.createDirectStream(jsc,
String.class, // key类型,偏移量
String.class, // 值类型
StringDecoder.class, //解码器
StringDecoder.class,
kafkaParameters,
topics);