kafka是什么?使用场景?
kafka是一个高吞吐的分布式消息队列系统。
特点:
生产者消费者模式
先进先出(FIFO)保证顺序
可靠性
自己不丢数据,
默认每隔7天清理数据。
消息列队常见场景:
系统之间解耦合、峰值压力缓冲、异步通信。
kafka生产消息、存储消息、消费消息
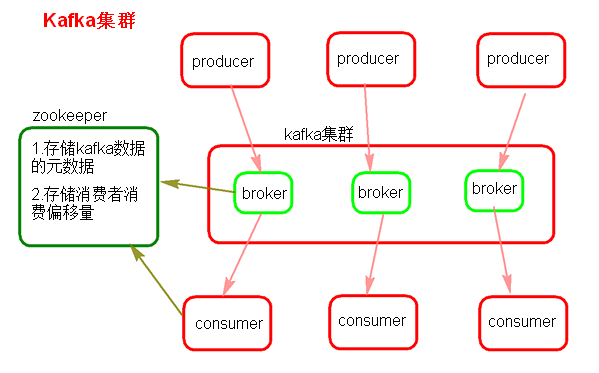
Kafka架构
producer (消息生存者)
broker (kafka集群的server,负责处理消息读、写请求,存储消息)
consumer ( 消息消费者)
zookeeper (元数据信息存在zookeeper中,包括:存储消费偏移量,topic话题信息,partition信息)
模型
topic
消息队列/分类,给消息分类
kafka里面的消息是有topic来组织的,简单的我们可以想象为一个队列就是一个topic(非严格的队列)
Partition
每个topic又分为很多个partition。
每个partition可以同时接受producer写,增加并行度,降低单点的磁盘压力
每个Partition存储层面是append log文件,消息会被追加到log文件尾部
所以在每个partition内部消息强有序,相当于有序的队列,partiton层面才是严格的FIFO
其中每个消息都有个序号offset,即偏移量,Long型,唯一标记
每个partition存储在不同的broker
即 一个partition对应一个broker,一个broker可以管多个partition
Segment
每个Partition物理上有多个segment组成
美团的文章,Kafka底层存储详解 : 转载: Kafka文件存储机制那些事
生产消费策略
producer自己决定往哪个partition里面去写
这里有一些的策略,譬如基于轮询的负载均衡策略,基于Hash的partition策略
Kafka不需要维护consumer消费的偏移量,consumer自己维护消费到哪个offset,默认写到zookeeper中。
每个consumer都有对应的group,group内是queue消费模型
各个consumer消费不同的partition,也就是一个消息只会被一个consumer消费,即一个消息在group内只消费一次
group间是publish-subscribe消费模型,各个group各自独立消费,互不影响,因此一个消息可以被每个group消费一次。
这个partition可以很简单想象为一个append log文件,当数据发过来的时候它就往这个partition上面append,追加就行,消息不经过内存缓冲,直接写入文件(零拷贝,不进入用户空间)。
kafka是根据时间策略删除,而不是消费完就删除,在kafka里面只有过期(消费完)这样一个概念。
默认一周后删除,没消费也删除。
kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉
kafka的特点
有消息系统的系统的特点:
生存者消费者模型,FIFO
Partition内部是FIFO的,partition之间呢不是FIFO的,即一个topic不是FIFO
当然我们可以把topic设为一个partition,这样就是严格的FIFO。
高性能:
单节点支持上千个客户端,百MB/s吞吐,接近网卡的极限
持久性:
消息直接持久化在普通磁盘上且性能好
直接写到磁盘中去,就是直接append到磁盘里去,这样的好处是直接持久化,数据不会丢失。
第二个好处是顺序写,然后消费数据也是顺序的读,所以持久化的同时还能保证顺序,比较好,因为磁盘顺序读比较好。
分布式:
数据副本冗余、流量负载均衡、可扩展
分布式,数据副本,也就是同一份数据可以到不同的broker上面去,也就是当一份数据,磁盘坏掉的时候,数据不会丢失。
比如3个副本,就是在3个机器磁盘都坏掉的情况下数据才会丢,在大量使用情况下看这样是非常好的。
负载均衡,可扩展,在线扩展,不需要停服务。
很灵活:
消息长时间持久化 +消费者自己维护消费状态
消费方式非常灵活,
第一原因是消息持久化时间跨度比较长,一天或者一星期等,
第二消费状态自己维护消费到哪个地方了可以自定义消费偏移量。
很灵活即Kafka做的工作很少,需要用户自己维护的多。
Partition的备份 replicas
· 每个Partition都有一个broker server 为leader,leader负责读写操作
多个 follow broker 单调同步 leader broker的 这个partition的信息,备份这个partition 。(可以没有由 broker的配置信息决定)
leader 和 follow 都将一条消息保存成功,消息才是 committed
follow落后太多或失效,会被leader从replicas同步列表中删除。
· 当一个broker停止或者crashes时,所有本来将它作为leader的 Partition 将会把leader转移到其他broker上去。
极端情况下,会导致同一个leader管理多个分区,导致负载不均衡。
同时当这个broker重启时,如果这个broker不再是任何分区的leader,kafka的client也不会从这个broker来读取消息,从而导致资源的浪费。
· 因此kafka中有一个被称为优先副本(preferred replicas)的概念。
如果一个分区有3个副本,且这3个副本的优先级别分别为0,1,2,根据优先副本的概念,0会作为leader 。当0节点的broker挂掉时,会启动1这个节点broker当做leader。
当0节点的broker再次启动后,会自动恢复为此partition的leader。不会导致负载不均衡和资源浪费,这就是leader的均衡机制。
在配置文件conf/ server.properties中配置开启(默认就是开启):
broker.id=0log.dirs=/var/bigdata/kafkazookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181zkServer.sh startbin/kafka-server-start.sh config/server.propertiesnohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic topic2017 --partitions 3 --replication-factor 3./kafka-console-producer.sh --topic topic2017 --broker-list node1:9092,node2:9092,node3:9092./kafka-console-consumer.sh --zookeeper node3:2181,node4:2181,node5:2181 --topic topic2017./kafka-topics.sh --list --zookeeper node3:2181,node4:2181,node5:2181./kafka-topics.sh --describe --zookeeper node3:2181,node4:2181,node5:2181 --topic topic2017
./zkCli.shls /brokers/topics/ls /consumersJAVA连接Kafka
KafkaProducer
package com.kafka;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
/**
* description:
* step1 : 创建存放配置信息的properties
* step2 : 将properties封装到ProducerConfig中
* step3 : 创建producer对象
* step4 : 发送数据流
*
* 执行过程:
* 1、创建一个topic
* kafka-topic.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic xxxx
* 2、运行本类中的代码
* 3、查看message
* kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic xxxx
* kafka
*/
public class KafkaProducer {
public static void main(String[] args) throws InterruptedException {
//step1 : 创建存放配置信息的properties
Properties props = new Properties();
/**
* 指定producer连接的broker列表
*/
props.put("metadata.broker.list", "node01:9092,node02:9092,node03:9092");
/**
* ack机制
* 0 which means that the producer never waits for an acknowledgement from the broker
* 1 which means that the producer gets an acknowledgement after the leader replica has received the data
* -1 The producer gets an acknowledgement after all in-sync replicas have received the data
*/
props.put("request.required.acks", "1");
//消息发送的同步与异步
props.put("producer.type", "sync");
/**
* 指定message的序列化方法,用户可以通过实现kafka.serializer.Encoder接口自定义该类,kafka.serializer.DefaultEncoder
* 默认情况下message的key和value都用相同的序列化,但是可以使用"key.serializer.class"指定key的序列化
*/
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 设置自定义的partition,当topic有多个partition时如何对message进行分区
// props.put("partitioner.class", "cn.com.dimensoft.kafka.SamplePartition");
// step2 : 将properties封装到ProducerConfig中
ProducerConfig config = new ProducerConfig(props);
// step3 : 创建producer对象,指定泛型 Producer的两个泛型,第一个指定Key的类型,第二个指定value的类型
Producer<String,String> producer = new Producer<String,String>(config);
//发送数据流
for (int i = 150; i < 200 ; i++) {
/**
* 第一个泛型指定用于分区的key的类型,第二个泛型指message的类型
* topic只能为String类型
*/
producer.send(new KeyedMessage<String, String>("dengchao" , "我是第 "+ i +" 号。"));
Thread.sleep(100);
}
producer.close();
}
}KafkaProducer
package com.kafka;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties;
/**
* description:
* step1 : 创建存放配置信息的properties
* step2 : 将properties封装到ConsumerConfig中
* step3 : 调用Consumer的静态方法创建ConsumerConnector
* step4 : 根据创建好的ConsumerConnector对象创建MessageStreams集合
* step5 : 根据具体的topic名称得到数据流KafkaStream
* step6 : 调用KafkaStream的iterator拿到ConsumerIterator对应,然后就可以迭代获得producer发送过来的消息了
*/
public class KafkaConsumer {
private ConsumerConnector connector ;
public KafkaConsumer() {
Properties props = new Properties();
props.put("zookeeper.connect","node01:2181,node02:2181,node03:2181");
//设置消费组id group设置在 /config/consumer.properties
props.put("group.id", "test-consumer-group");
//下面这2个参数需要设置,否则consumer每次启动都会从头开始读取数据
//自动提交到 zk 注意offset信息并不是每消费一次消息就向zk提交一次,而是现在本地保存(内存),并定期提交
//可以设置为false 自己手动调用consumer中的commit 方法(其实是讲message中存在的offset信息提交到zk上进行存储)
props.put("auto.commit.enable", "true");
//自动提交的时间间隔,默认为1分钟 这里是1秒
props.put("auto.commit.interval.ms", "1000");
//在Consumer在ZooKeeper中发现没有初始的offset时或者发现offset不在范围呢,该怎么做:
//smallest : 自动把offset设为最小的offset。
//largest : 自动把offset设为最大的offset。
//anything else: 抛出异常
props.put("auto.offset.reset", "smallest");
//request.required.acks=0 时的问题
//问题:当consumer消费失败后,会导致消息丢失;改进:每次consumer消费后,给broker ack,若broker在超时时间未收到ack,则重发此消息。
//问题:1.当消费成功,但未ack时,会导致消费2次
// 2. now the broker must keep multiple states about every single message
// 3.当broker是多台机器时,则状态之间需要同步
props.put("request.required.acks", 1);
//指定序列化处理类,默认为kafka.serializer.DefaultEncoder
props.put("serializer.class", "kafka.serializer.StringEncoder");
// step2 : 将properties封装到ConsumerConfig中
ConsumerConfig config = new ConsumerConfig(props);
// step3 : 调用Consumer的静态方法创建ConsumerConnector
connector = Consumer.createJavaConsumerConnector(config);
}
public static void main(String[] args) {
try {
new KafkaConsumer().consumer();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void consumer() throws InterruptedException{
// step4 : 根据创建好的ConsumerConnector对象创建MessageStreams集合
Map<String,Integer> topicCountMap = new HashMap<String,Integer>();
// 描述读取哪几个topic,该topic需要几个线程读
topicCountMap.put("dengchao", 1);
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
// 根据填充好的map获得streams集合
// a map of (topic, list of KafkaStream) pairs
Map<String, List<KafkaStream<String, String>>> streams = connector.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
// step5 : 根据具体的topic名称得到数据流KafkaStrea
// 每个线程对应于一个KafkaStream
KafkaStream<String, String> kafkaStream = streams.get("dengchao").get(0);
// step6 : 调用KafkaStream的iterator拿到ConsumerIterator
// 然后就可以迭代获得producer发送过来的消息了
ConsumerIterator<String, String> iterator = kafkaStream.iterator();
MessageAndMetadata<String, String> mm = null;
while( iterator.hasNext() ){
mm = iterator.next();
System.out.println("partition : " + mm.partition() + " , message : " + mm.message());
Thread.sleep(50);
}
}
}