数据本地性
Application任务执行流程:
在Spark Application提交后,Driver会根据action算子划分成一个个的job,
然后对每一个job划分成一个个的stage,stage内部实际上是由一系列并行计算的task组成的,然后以TaskSet的形式提交给TaskScheduler
TaskScheduler在进行分配之前都会计算出每一个task最优计算位置。
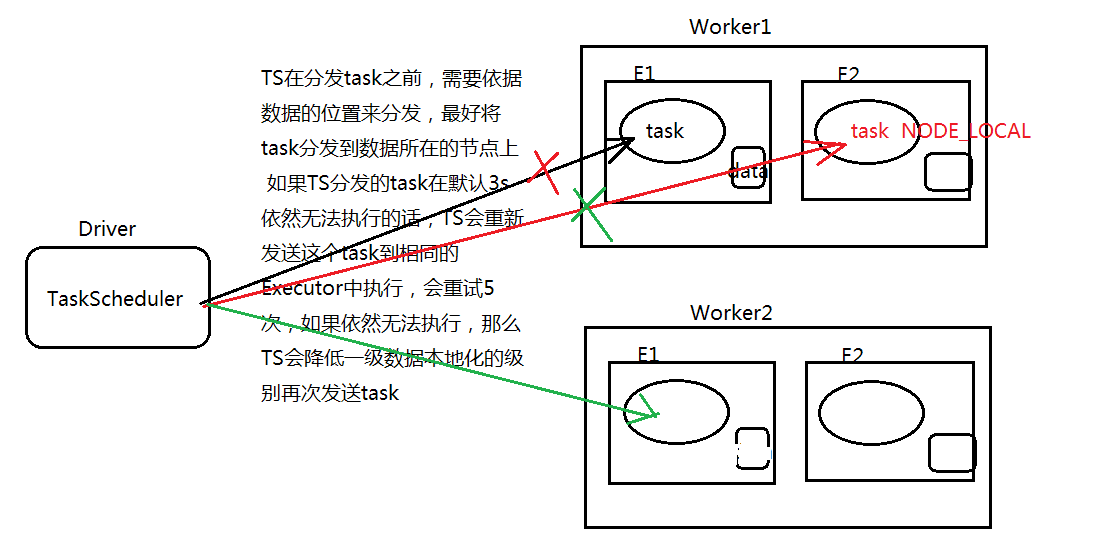
Spark的task的分配算法优先将task发布到数据所在的节点上,从而达到数据最优计算位置。
而将 分配task到节点上,就是 依据数据本地化级别 的:
TaskScheduler在分发task之前,需要依据数据的位置来分发,最好是将task分发到数据所在的节点 (最高级别)上。
Spark中涉及的数据位置,基本就三种:
一是数据的来源是HadoopRDD;。
二是RDD的数据来源来自于RDD Cache(即由CacheManager从BlockManager中读取,或者Streaming数据源RDD)。其它情况下,从其他数据源读取数据(MySQL),不存在判断Locality本地性的问题。
三是ShuffleRDD,其本地性始终为No Prefer,因此其实也无所谓 Locality。
如果TaskScheduler分发的task在 默认3s后依然无法执行 的话(可能在Exector线程池中等待执行),就会 重新发送这个task 到相同的Exector中执行。
如果 重试5次后 依然无法执行,那么TaskScheduler会降低一级数据本地化级别 来再次发送 task
数据本地化级别
PROCESS_LOCAL 进程本地化
task要计算的数据再本进程的内存中
NODE_LOCAL 节点本地化
1、task要计算的数据,在本节点的其他的Executor进程中。
2、task要计算的数据,在本节点的磁盘上
NO_PREF 没有优先级
例如数据在MySQL或Redis中,这时设置优先级就没有意义
RACK_LOCAL 机架本地化
task要计算的阿数据在同一个机架的不同节点磁盘上或Executor进程内存中。
ANY 任何、机房本地化
任一节点上都可以
如何查看数据本地化级别呢?
日志、Web UI
配置参数
spark.locality.wait 数据本地性降级的等待时间,默认值3000ms
spark.locality.wait.process 多长时间等不到PROCESS_LOCAL就降级,默认值为 ${ spark.locality.wait }
spark.locality.wait.node 多长时间等不到 NODE_LOCAL就降级,默认值为 ${ spark.locality.wait }
spark.locality.wait.rack 多长时间等不到 RACK_LOCAL就降级,默认值为 ${ spark.locality.wait }
注意:
如果你的任务数量较大和单个任务运行时间比较长 的情况下,单个任务是否在数据本地运行,代价区别可能比较显著, 如果数据本地性不理想,那么调大这些参数 对于性能优化可能会有一定的好处。
反之如果等待的代价超过带来的收益(等待时间大于了数据移动时间),那就反而会拖累Application的执行时间
特别值得注意的是:
在处理应用刚启动后提交的第一批任务时,由于当作业调度模块开始工作时,处理任务的Executors可能还没有完全注册完毕,因此一部分的任务会被放置到No Prefer的队列中,从而被优先分配到非本地节点执行,如果的确没有Executors在对应的节点上运行,或者的确是No Prefer的任务(如shuffleRDD),这样做确实是比较优化的选择,但是这里的实际情况只是这部分Executors还没来得及注册上而已。这种情况下,即使加大本节中这几个参数的数值也没有帮助。
针对这个情况,有一些已经完成的和正在进行中的PR通过例如动态调整No Prefer队列,监控节点注册比例等等方式试图来给出更加智能的解决方案。不过,你也可以根据自身集群的启动情况,通过在创建SparkContext之后,主动Sleep几秒的方式来简单的解决这个问题。