鲁棒性调优
下述两个公式描述同一条直线,哪个好?
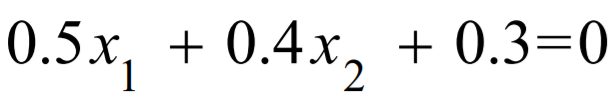
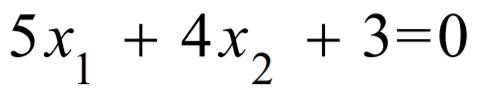
第一个公式更好:
因为W的数值越大的,所以 带入一个很大的X 与 带入一个很小的X,其结果会差别很大。 而第一个会差别较小,
也是预测值随着输入数据的变化的幅度会小,即较能抵抗数据的扰动。
所以W的参数越小,所以这个模型的推广能力(泛化能力) 越强,但是预测准确度也越小。
但是W的值也不能无限小,无限小的化,预测值就几乎不会随着X变化了,
那如何寻找到一个合适大小的W呢?
模型预测的正确率是由误差值的决定的,而等比例减小w的值,会降低正确率,
所以可以通过重写误差函数来找到合适的w大小
两种方式定义这组w的大小 , L1与L2:
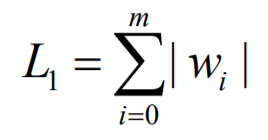
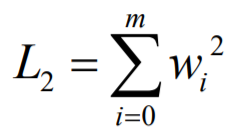
重写误差函数, 牺牲正确率来提高推广能力

lambda是W的权重 , 即由 lambda 决定这个模型推广的能力,值越大,再模型的求导过程中,对误差值方程的影响也就越大,也就越偏向于推广能力
一般0.4,不超过1
L1 与 L2区别:
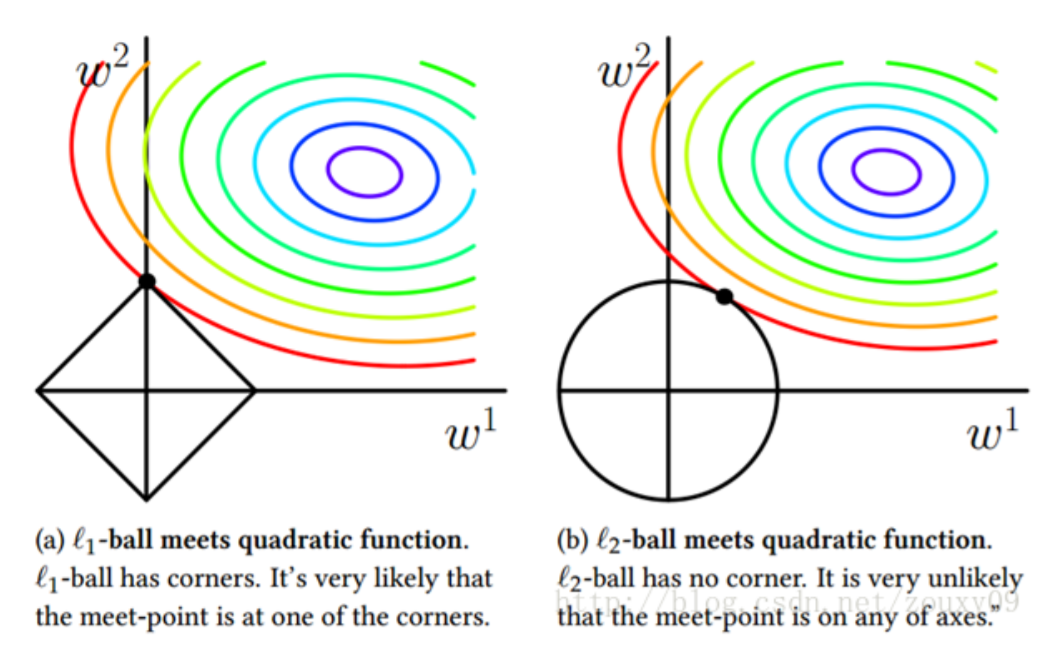
图中彩色圆为误差方程左边部分, L1为左图矩形,L2为右图圆
由图可得:
L1 趋于与圆交于矩形顶点 , 即倾向于使得w要么取1,要么取0,稀疏编码
适用场景:由于某些w会取0,适合降低维度
L2 处于与圆交于圆的非轴部分,即倾向于使得w整体偏小,岭回归
适用场景:L2使整体w减小,所以适合大部分场景
object LogisticRegression5 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("spark").setMaster("local[3]")
val sc = new SparkContext(conf)
val inputData = MLUtils.loadLibSVMFile(sc, "健康状况训练集.txt")
val splits = inputData.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
val lr = new LogisticRegressionWithLBFGS()
lr.setIntercept(true)
// lr.optimizer.setUpdater(new L1Updater)
lr.optimizer.setUpdater(new SquaredL2Updater)
// 这块设置的是我们的lambda,越大越看重这个模型的推广能力,一般不会超过1,0.4是个比较好的值
lr.optimizer.setRegParam(0.4)
val model = lr.run(trainingData)
val result=testData
.map{point=>Math.abs(point.label-model.predict(point.features)) }
println("正确率="+(1.0-result.mean()))
println(model.weights.toArray.mkString(" "))
println(model.intercept)
}
}