Spark内存管理
Spark执行应用程序时,Spark集群会启动 Driver和Executor两种JVM进程,
Driver: 负责创建SparkContext上下文,提交任务,task的分发等。
Executor: 负责task的计算任务,并将结果返回给Driver。同时需要为需要持久化的RDD提供储存。
Driver端的内存管理比较简单,这里所说的Spark内存管理针对Executor端的内存管理。
Spark内存管理分为静态内存管理和统一内存管理,Spark1.6之前使用的是静态内存管理,Spark1.6之后引入了统一内存管理。
一、静态内存管理
静态内存管理类(StaticMemoryManager)源码
/**
* A [[MemoryManager]] that statically partitions the heap space into disjoint regions.
* // 主要分为 运算 和 存储 区域
* The sizes of the execution and storage regions are determined through
* `spark.shuffle.memoryFraction` and `spark.storage.memoryFraction` respectively.
* The two regions are cleanly separated such that neither usage can borrow memory from the other.
*/
private[spark] class StaticMemoryManager(首先总的内存分为3个部分
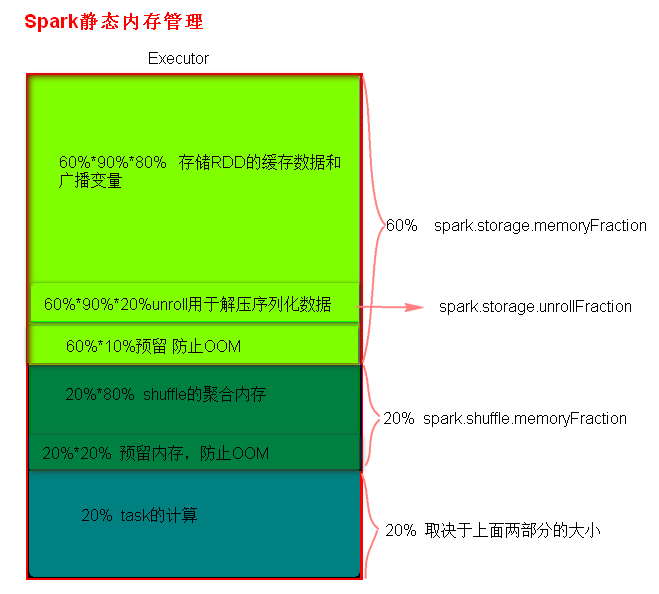
(1)、存储内存区域:
占用60%内存
由 spark.storage.memoryFraction 指定,默认值:0.6
(2)、shuffle内存区域
占用20%内存
由 spark.shuffle.memoryFraction 指定,默认值0.2
(3)、task运算内存区域
占用 100% - 60% - 20% = 20% 内存
不能指定,指定另外两个,剩下的即为此内存大小
存储内存区域 (60%)又分为两个区域
/**
* Return the total amount of memory available for the storage region, in bytes.
*/
private def getMaxStorageMemory(conf: SparkConf): Long = {
// Executor 最大可用内存大小
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
// 存储区域内存
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
// 存储区域的 可安全 使用的内存比例
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
// 相乘得 可安全 使用的内存大小
(systemMaxMemory * memoryFraction * safetyFraction).toLong
} 1、(可安全使用的区域)存储RDD持久化数据以及广播变量 和 用于数据反序列化
占用此区域90%内存 (60% * 90%)
由 spark.storage.safetyFraction 指定,默认值0.9
其中又分为两个区域
· 用于数据反序列化
占用此区域20%内存 (60% * 90% * 20%)
由 spark.storage.unrollFraction 指定,默认值0.2
// Max number of bytes worth of blocks to evict when unrolling
private val maxUnrollMemory: Long = {
(maxStorageMemory * conf.getDouble("spark.storage.unrollFraction", 0.2)).toLong
}· 存储RDD持久化数据以及广播变量
占用此区域70%内存 (60% * 90% * 70%)
不能指定,占用90%除去序列化使用的剩余内存。
2、预留出来的区域,用于防止OOM以及给JVM本身使用
占用此区域10%内存
不能指定,由 100% - 90% 得
shuffle内存区域 (20%)又分为两个区域
/**
* Return the total amount of memory available for the execution region, in bytes.
*/
private def getMaxExecutionMemory(conf: SparkConf): Long = {
// Executor 最大可用内存大小
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
// shuffle聚合 区域内存比例
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
// shuffle聚合 区域内存 可安全使用的比例
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
// 相乘得 可安全 使用的内存大小
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}1、用于shuffle聚合的内存
占用 80% (20% * 20%)
由 spark.shuffle.safetyFraction 指定,默认值0.8
2、预留出来用于防止OOM
占用此区域20%内存
不能指定,由 100% - 80% 得
二、统一的内存管理
统一内存管理类(UnifiedMemoryManager )源码
/**
* A [[MemoryManager]] that enforces a soft boundary between execution and storage such that
* either side can borrow memory from the other.
*
* The region shared between execution and storage is a fraction of (the total heap space - 300MB)
* configurable through `spark.memory.fraction` (default 0.75). The position of the boundary
* within this space is further determined by `spark.memory.storageFraction` (default 0.5).
* This means the size of the storage region is 0.75 * 0.5 = 0.375 of the heap space by default.
*
* Storage can borrow as much execution memory as is free until execution reclaims its space.
* When this happens, cached blocks will be evicted from memory until sufficient borrowed
* memory is released to satisfy the execution memory request.
*
* Similarly, execution can borrow as much storage memory as is free. However, execution
* memory is *never* evicted by storage due to the complexities involved in implementing this.
* The implication is that attempts to cache blocks may fail if execution has already eaten
* up most of the storage space, in which case the new blocks will be evicted immediately
* according to their respective storage levels.
*
* @param storageRegionSize Size of the storage region, in bytes.
* This region is not statically reserved; execution can borrow from
* it if necessary. Cached blocks can be evicted only if actual
* storage memory usage exceeds this region.
*/
private[spark] class UnifiedMemoryManager private[memory] (分为 2 个部分
/**
* Return the total amount of memory shared between execution and storage, in bytes.
*/
private def getMaxMemory(conf: SparkConf): Long = {
// Executor 内存 大小
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
// spark.testing.reservedMemory
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
val minSystemMemory = reservedMemory * 1.5
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please use a larger heap size.")
}
// 根据当前JVM的启动内存,减去300MB , Executor 可用内存 大小
val usableMemory = systemMemory - reservedMemory
// task用的 运算与存储 内存
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.75)
(usableMemory * memoryFraction).toLong
} 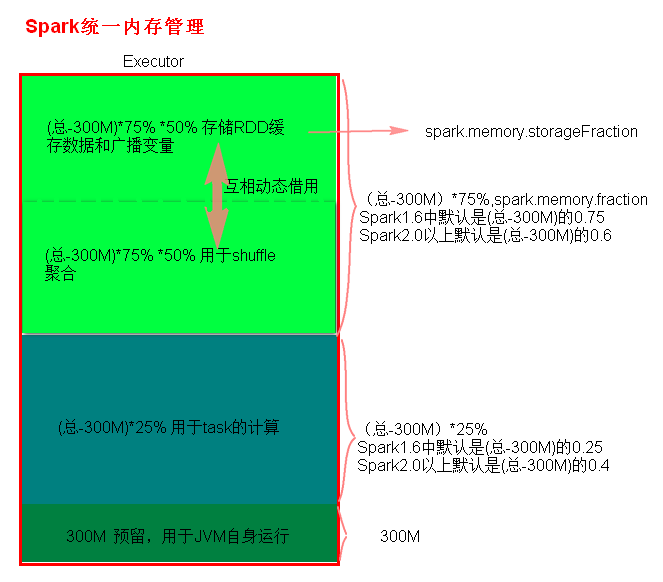
(1)、留给JVM的内存
默认值 300M
由 spark.testing.reservedMemory 指定
(2)、 task运算与存储的内存
默认值: Excutor内存大小 - 300M
其中又分为 2 个区域
1、存储区域
占用内存: 75%
由 spark.memory.fraction 指定,默认值 0.75。
其中分为 2 个区域
· 存储RDD持久化数据以及广播变量
占用内存: 50%
由 spark.memory.storageFraction 指定,默认值 0.5。
def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {
val maxMemory = getMaxMemory(conf)
new UnifiedMemoryManager(
conf,
maxMemory = maxMemory,
// 存储 内存
storageRegionSize =
(maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong,
numCores = numCores)
}· shuffle聚合内存
占用内存: 50%
不能指定,占用中存储区域剩下的。
2、 运算区域
占用内存: 25%
不能指定,100% - 25%。