如果一个变量在Driver端定义,再在算子中被修改,然后又想在Driver端取到修改后结果。
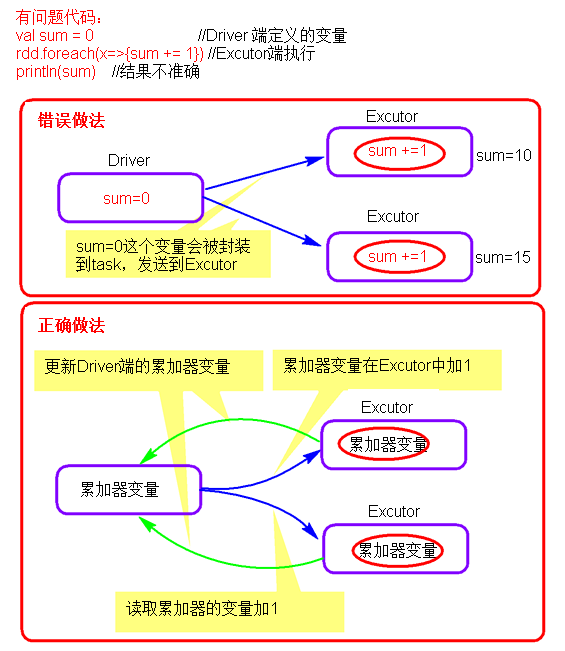
那上面的例子是做不到的:
因为该变量在Driver定义,而算子中的代码逻辑是在Executor中执行的,Spark会把这个变量复制一份给Executor,所以Driver中的变量并没有改变,也就得不到修改后的值。
而使用Accumulator可以解决这个问题
累加器相当于集群规模的变量
def accumulator() = {
val conf = new SparkConf();
conf.setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
/**
* 累加器只能在Driver端定义,因为需要SparkContext
* 累加器在executor端操作(累加)
* 累加器只能在Driver端读取,不能在executor端读取
*
* sc.accumulator(初始值) 会返回一个累加器
*/
val count = sc.accumulator(0)
val list = List(1,2,3,4,5,6,6)
val rdd1 = sc.parallelize(list)
var rdd2 = rdd1.filter( x => {
count += x
true
}).count();
println(count)
sc.stop()
}累加器只能在Driver端定义,因为需要SparkContext
累加器在executor端修改(累加)
累加器只能在Driver端读取,不能在executor端读取
自定义累计器:
import com.bjsxt.spark.constant.Constants;
import com.bjsxt.spark.util.StringUtils;
import org.apache.spark.AccumulatorParam;
public class MonitorAndCameraStateAccumulator implements AccumulatorParam<String> {
@Override
public String addInPlace(String v1, String v2) {
return add(v1, v2);
}
/**
* 初始化的值
*/
@Override
public String zero(String v1) {
return Constants.FIELD_NORMAL_MONITOR_COUNT+"=0|"
+ Constants.FIELD_NORMAL_CAMERA_COUNT+"=0|"
+ Constants.FIELD_ABNORMAL_MONITOR_COUNT+"=0|"
+ Constants.FIELD_ABNORMAL_CAMERA_COUNT+"=0|"
+ Constants.FIELD_ABNORMAL_MONITOR_CAMERA_INFOS+"= ";
}
@Override
public String addAccumulator(String v1, String v2) {
return add(v1, v2);
}
/**
* @param v1 连接串,上次累加后的结果
* @param v2 本次累加传入的值
* @return 更新以后的连接串
*/
private String add(String v1, String v2) {
if(StringUtils.isEmpty(v1)){
return v2;
}
String[] valArr = v2.split("\\|");
for (String string : valArr) {
String[] fieldAndValArr = string.split("=",2);
String field = fieldAndValArr[0];
String value = fieldAndValArr[1];
String oldVal = StringUtils.getFieldFromConcatString(v1, "\\|", field);
if(oldVal != null){
if(Constants.FIELD_ABNORMAL_MONITOR_CAMERA_INFOS.equals(field)){
v1 = StringUtils.setFieldInConcatString(v1, "\\|", field, oldVal + "~" + value);
}else{
int newVal = Integer.parseInt(oldVal)+Integer.parseInt(value);
v1 = StringUtils.setFieldInConcatString(v1, "\\|", field, String.valueOf(newVal));
}
}
}
return v1;
}
}广播变量
由以上累加器可以知道 算子中是可以使用 Driver端定义的变量的,但是这个有一个问题,因为它会把这个变量给 每个Task 复制一份,如果这个变量小倒还没事,但是这个变量占用内存大的话,那就会对网络和内存都是大的负担,这个可以使用广播变量来解决这个问题:
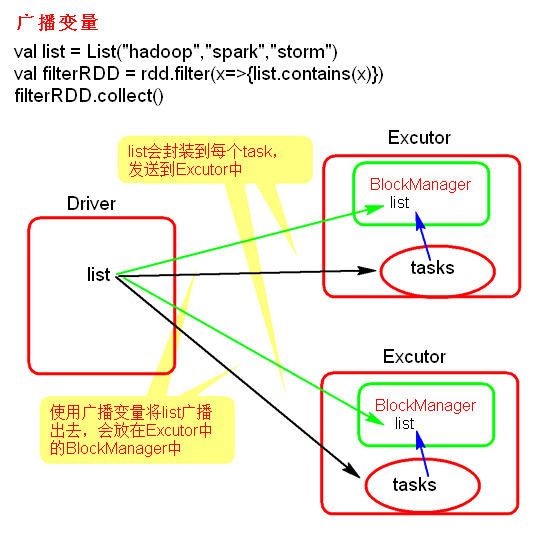
广播变量只会在 每个Executor 上保存一个变量的副本
相当于集群规模的常量
广播变量有三个注意点:
广播变量只能在Driver端定义,因为需要SparkContext
广播变量可以在Driver端修改
广播变量只能在Executor读取,不能修改
问题:RDD可以被广播变量广播出去吗?
首先RDD是不能广播的,因为RDD本身是不存储数据,它存储的只是逻辑。
如果要广播RDD里的数据,那么可以 先用 collect 算子将数据拉取到 Driver 端,再将数据集合广播出去。
// 对listRDD中值过滤掉filterRdd中有的
def broadcast() = {
val conf = new SparkConf();
conf.setMaster("local").setAppName("broadcast")
val sc = new SparkContext(conf)
val filterRdd = sc.makeRDD(List("张三","李四"))
val listRDD = sc.makeRDD(List("我是张三!","我是jeff!","我是dc!","我是李四!","我是张三!","我是devin!","我是张三!",
"我是pj!","我是张三!","我是zxy!","我是xy!","我是张三!","我是李四!","我是lxinr!"))
// collect 算子拉取到Driver端
val filterList = sc.broadcast(filterRdd.collect())
val rdd = listRDD.filter(x => {
var count = 0
filterList.value.foreach(filterWord => {
if (x.contains(filterWord)) {
count += 1
}
})
if (count == 0) {
true
} else {
false
}
})
rdd.collect().foreach(println)
sc.stop()
}