Hadoop 2.x 产生背景
Hadoop1.x 问题:
HDFS和MapReduce在高可用、扩展性等方面存在问题
HDFS 1.x 问题:
NameNode单点故障,难以应用于在线场景
NameNode压力过大,且内存受限,影响系统扩展性 – MapReduce存在的问题
JobTracker访问压力大,影响系统扩展性
难以支持除MapReduce之外的计算框架,比如Spark、Storm等
hadoop 2.x 诞生
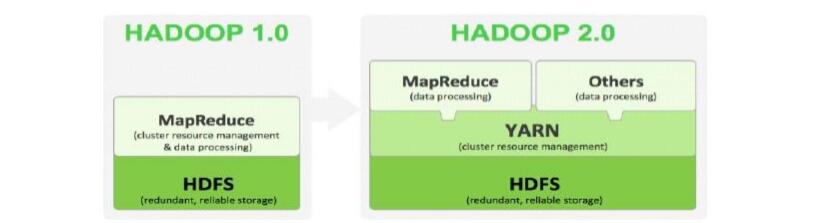
Hadoop 2.x由 HDFS、MapReduce 和 YARN 三个分支构成:
HDFS 2.x:NNFederation、HA
MapReduce:运行在YARN上的MR
YARN:资源管理系统
对HDFS使用者透明;
HDFS1.x中的命令和API仍可以使用;
HDFS 2.x
hdfs问题既namenode问题:namenode单点故障与内存受限
(一)、hdfs ha
集群高可用方案推导思维过程:
hdfs高可用既namenode高可用
首先namenode数据分为常量元数据和变量元数据,要实现数据一致性
一、首先要看常量元数据:
常量元数据由客户端提交,因为客户端只和主namenode联系,那备机就要实时备份常量元数据(edit log等)
如何同步呢?
1、首先最简单的就是用NFS文件系统,在linux中让主备机器都把一个目录映射到NFS文件系统上,这个主namenode写日志的时候,从namenode也能实时得到
2、但是这又会引发另外一个问题,那NFS机器宕机了呢?不就不可用了吗?
这就在解决问题的设计到的一个原则:不能为解决问题而又引发另外一问题,
所以就有 一变多 的解决方案,将 存储editlog的机器变为集群存储,这样能解决数据可用的问题
机器一变多也会引出问题,如何处理数据一致性?
强一致性:
就是在一次提交,在每台机器都写成功后才确认提交成功,
所以强一致性会 导致可用性 的问题,假如最后一台因为网络问题一直写不上去,会导致服务一直不可用
弱一致性(最终一致性)
就只有几台机器写成功后就可以确认写入成功,以后再将数据同步到其他机器,取数据时先更新版本再返回,故为最终一致性
那写入多少台算写入成功呢?说明这个问题之前首先来看看因为弱一致性引出的 脑裂问题?
从客户端的角度来看,当向某个集群节点提交一个写请求后,返回写入成功,客户端会认为是整个集群给它返回确认成功了,而不是某个节点成功了,那如何让某个节点的状态能代表整个集群的状态呢?
有种情况会导致脑裂:
假如一个集群四个节点,其中一个节点因为网络波荡不能和其他节点通信,而其他节点正常。
这时如果有客户端对这个节点提交写请求,如果写完之后节点也返回成功的话,这时就会脑裂,因为这个节点的数据状态跟其他节点是不一样,它们之间不能通信的,相当于形成了两个集群(脑裂)
如何解决呢脑裂? 解决方法:让因为不能通信形成的两个集群自己判断自己是不是多数集群
当自己能通信的机器个数为多数时,就提供服务,当不是时,就自杀进程停止服务,让客户端自己去连接其他节点
判断多数当然就是能 通信机器数量过半 了,这也解决第一个问题,当写入过半的机器算写成功
而这里因为过半有一个发现:
(1)、集群机器数奇数偶数至多可宕机数一样
当一个集群机器数为N(N为偶数),因为需要活着的机器需要过半才能提供服务,所以最多能宕机的机器数为 n - (n/2 + 1) = n/2 - 1, 当机器数为4时,最多能宕机的数量为1
当集群机器数N为奇数时,最多能宕机的机器数为 n - (n+1)/2 = n-1 / 2,当机器数为3时,最多能宕机的数量为1
也就是当集群数量为奇数N和N+1时,最多能宕机的数量都是一样的,所以集群一般设置为奇数个。
(2)、当集群数量为偶数时,当网络风暴使得形成两个分区,分区机器数刚好为一半的情况:
在这种情况下两个分区机器数都没有过半,使得两分区的机器都down了,服务就不可用了,
而数量为奇数的集群分成两个分区不会出现在这种情况,所以这里也推导出集群数量应该是奇数的。
二、变量元数据
变量元数据是有datanode上传给namenode的,这时 只需要datanode上传的时候给备namenode也上传一份就可以 了
这时注意备namenode不能多,因为多了那网络带宽全被上传元数据的心跳占了
主备NameNode 解决单点故障
active NameNode对外提供服务,standby NameNode同步主NameNode元数据, 以待切换
所有DataNode同时向两个NameNode汇报数据块信息,
两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。
两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。
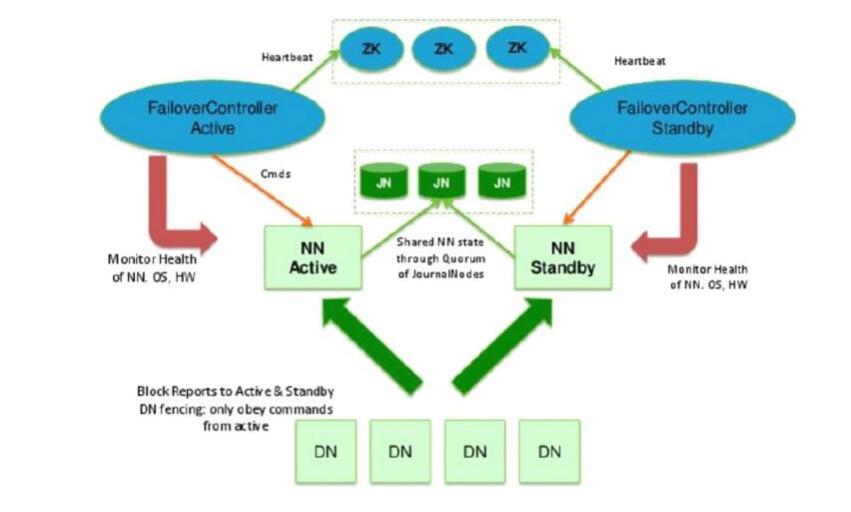
主备两种切换选择
手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
自动切换:基于Zookeeper实现(zk集群个数一般>=3)
ZookeeperFailoverController:ZKFC 部署在NameNode上,监控当前nn运行的健康状态,通过心跳汇报zookeeper,监控NN的active和standby状态,并向Zookeeper注册NameNode事件
NameNode挂掉后或ZKFC进程挂掉后,另一ZKFC执行回调事件,将将所在namenode设为active,将另一个namenode设为standby
Journalnode集群
active namenode和standby namenode之间通过JN集群(journalnode,QJM方式)来同步数据。( JN个数一般为>=3 的奇数 )
active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到 JN中。
standby namenode定期的检查,从JN把最近的edit文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage,
合并完成之后会通知active namenode获取这个新fsimage, active namenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。这样,保持了active namenode和standby namenode的数据的实时同步
(二)、HDFS Federation (联邦)
为解决内存受限问题
通过多个namenode把元数据的存储和管理分散到多个节点中,使到namenode可以通过增加机器来进行水平扩展。
可以通过多个namespace来隔离不同类型的应用把不同类型应用的hdfs元数据的存储和管理分派到不同的namenode中。
不同namenode底部使用同一批datanode。
原理即使对访问进行分类,不同的类型的访问交给不同的NameNode处理,来解决内存受限的问题。
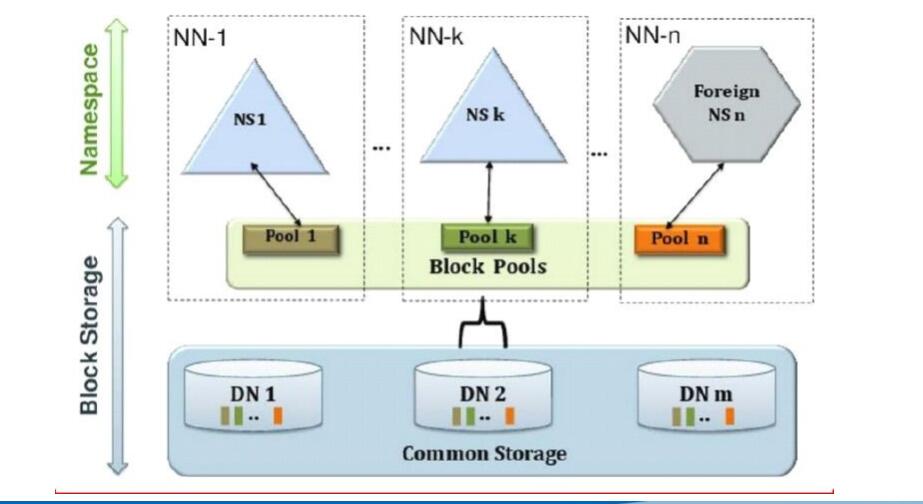
两种情况:
(1)、当公司两个两个项目组想使用同一批datanode节点,就配置两个namenode,让其管理各自的数据,互相隔离

(2)、当公司同一 项目组数据量太大,配置多少namenode管理不同类型的数据,解决内存受限,在namenode上层封装一个总的逻辑层,让其统筹管理分发不同类型数据请求
Federation的不足:
【单点故障问题】
HDFS Federation并没有完全解决单点故障问题。
虽然namenode存在多个,但是从单个namenode看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。
Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主nn挂掉一下,用于还原元数据信息。
【负载均衡问题】
HDFS Federation采用了Client Side Mount Table分摊文件和负载,该方法更多的需要人工介入已达到理想的负载均衡。
YARN
YARN:YetAnotherResourceNegotiator;
Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的;
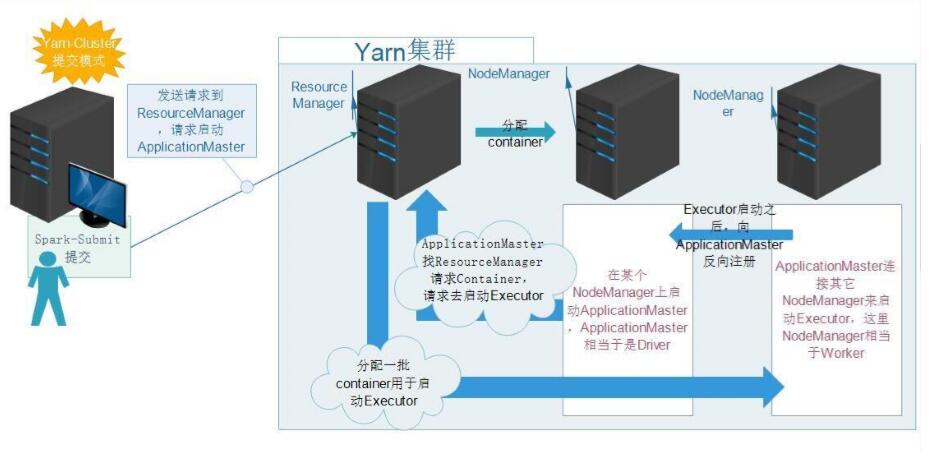
核心思想:将MRv1中 JobTracker 的资源管理和任务调度两个功能分开, 分别由ResourceManager和ApplicationMaster进程实现 ;
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务,调度Container,比如任务调度、任务监控和容错等,随机在一台nodemanager上启动,降低RS压力
NodeManager:负责管理某一节点的资源,管理Container生命周期,位于 datanode上
Container:具体task计算进程,默认NodeManager启动线程监控Container大小,超出申请资源额度,kill,支持Linux内核的Cgroup
YARN的引入,使得多个计算框架可运行在一个集群中
每个应用程序对应一个ApplicationMaster;
目前多个计算框架可以运行在YARN上,比如MapReduce、Spark、 Storm等
MapReduce On YARN
将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTracker构建的 MRv1中(MRv1直接与HDFS交互);
基本功能模块
YARN:负责资源管理和调度;
MRAppMaster:负责任务切分、任务调度、任务监控和容错等 ;
MapTask/ReduceTask:任务驱动引擎,与MRv1一致
每个MapRduce作业对应一个MRAppMaster
MRAppMaster任务调度
YARN将资源分配给MRAppMaster
MRAppMaster进一步将资源分配给内部的任务
MRAppMaster容错
失败后,由YARN重新启动
任务失败后,MRAppMaster重新申请资源