hsfs 2.x ha 搭建
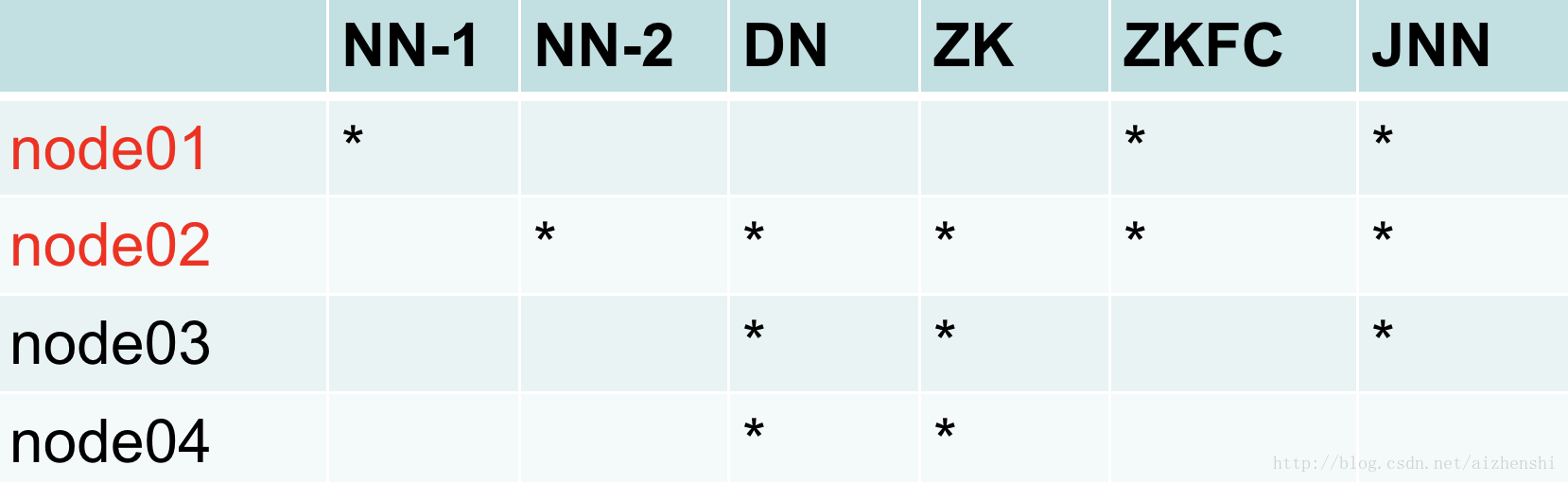
节点图
准备
1. 设置网络IP 、/etc/hosts 、关闭防火墙、jdk环境变量
设置四台服务器时间同步(需安装 yum install ntp -y)
ntpdate ntp.aliyun.com2. 设置免密钥
每一台NN 需要免密钥登录到其他任意一台机器
每一个节点执行ssh-keygen生成私钥与公钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 在node01,node02执行下面命令,让两台namenode能登陆所有节点,两台NN本地连接也要必须免密钥
ssh-copy-id -i ~/.ssh/id_dsa.pub root@node01
ssh-copy-id -i ~/.ssh/id_dsa.pub root@node02
ssh-copy-id -i ~/.ssh/id_dsa.pub root@node03
ssh-copy-id -i ~/.ssh/id_dsa.pub root@node04安装zookeeper
1. 在node02、03、04上安装Zookeeper集群
tar xf zp.tar.gz -C /opt/devel/ 配置zookeeper的环境变量 ,ZOOKEEPER_PREFIX与PATH添加bin
vi /etc/profile
重命名/opt/devel/zookeeper/conf/下 zoo.sample.cfg -> zoo.cfg
dataDir=/var/bigdata/zookeeper
clientPort=2181
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888 (1、2、3为设置的zk节点的id)
( zookeeper配置详解 http://www.cnblogs.com/yuyijq/p/3438829.html)
同步配置文件至其他zk节点上
scp ./zoo.cfg node02:`pwd`
scp ./zoo.cfg node03:`pwd` 创建文件myid(/var/bigdata/zookeeper/myid)
mkdir /var/bigdata/zookeeper 每台zookeeper 输出集群每个节点zoo.cfg配置的各自id到myid
node01中
echo 1 > myid 其他zk node中
echo 这个节点zoo.cfg中设置的id > myid
安装hadoop
1. 安装hadoop包
tar xf hadoop-2.6.5.tar.gz -C /opt/devel/修改 /etc/profile文件,添加 配置环境变量 HADOOP_PREFIX,bin和sbin加入PATH目录
. /etc/profile下面配置hdfs-site.xml、core-site.xml、salves,先配置node01
2. 配置hdfs-site.xml
如果前面配置了1.X完全分布式,可以先备份配置文件
cd /opt/devel/hadoop-2.6.5/etc/
cp -r hadoop hadoop-fullcd /opt/devel/hadoop-2.6.5/etc/hadoop/
vi hdfs-site.xml 添加
(1)、配置dfs.nameservices
这个名字不能由下划线_ 而 -可以 (惨痛经历)
<property>
<name>dfs.nameservices</name>
<value>nn-cluster</value>
</property> (2)、配置nameservices中的namenode / dfs.ha.namenodes
#nn1,nn2 为namenode设置的id (非必要为域名)
#记得修改<name>dfs.ha.namenodes.mycluster</name>为<name>dfs.ha.namenodes.nn-cluster</name>
#下面的配置都要注意这个问题
<property>
<name>dfs.ha.namenodes.nn-cluster</name>
<value>nn1,nn2</value>
</property> (3)、配置namenode具体地址rpc-address
(RPC:远程过程调用 它允许一台计算机程序远程调用另外一台计算机的子程序)
<property>
<name>dfs.namenode.rpc-address.nn-cluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nn-cluster.nn2</name>
<value>node02:8020</value>
</property> (4)、重新配置http-address
<property>
<name>dfs.namenode.http-address.nn-cluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.nn-cluster.nn2</name>
<value>node02:50070</value>
</property> (5)、删除hadoop 1.x 配置的dfs.namenode.secondary.http-address
因为secondarynode的功能由处于的standby namenode 代替
(6)、配置qjournal node地址 (官方建议qjournal id 与 nameservices id 用同一个)
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/nn-cluster</value>
</property> (7)、dfs.journalnode.edits.dir 这是JournalNode进程保持逻辑状态的路径。这是在linux服务器文件的绝对路径。
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/journal</value>
</property> (8)、dfs.client.failover.proxy.provider.[nameservice ID]
the Java class that HDFS clients use to contact the Active NameNode
这里配置HDFS客户端连接到Active NameNode的一个java类。
<property>
<name>dfs.client.failover.proxy.provider.nn-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> (9)、配置 a list of scripts or Java classes which will be used to fence the Active NameNode during a failover
dfs.ha.fencing.ssh.private-key-files 为使sshfence能登录到 宕机的仍试图写入qjournal node 的namenode进程杀死此进程,为其配置一个私钥(注意rsa 和 dsa 别写混了)。
( 或者配置一个同户名密码端口 文档里有,或者配置shell 来 fence the Active NameNode)
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property> (10)、这里配置的使zookeeper集群与hadoop的联系,而zoo.cfg中配置的使zk集群中各zk节点的联系,
zookeeper自动故障转移配置需要两个新的参数来配置,还有一个配置在core-site.xml中
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>3. 配置core.site.xml
(1)、 fs.defaultFS
the default path prefix used by the Hadoop FS client when none is given
客户端连接HDFS时,默认的路径前缀
fs.defaultFS的值表示hdfs路径的逻辑名称。因为我们会启动2个NameNode,每个NameNode的位置不一样,那么切换后,用户也要修改代码,很麻烦,因此使用一个逻辑路径,用户就可以不必担心NameNode切换带来的路径不一致问题了
<property>
<name>fs.defaultFS</name>
<value>hdfs://nn-cluster</value>
</property> (2)、 集群设置为自动故障转移时配置以下
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property> core-site.xml在原来hadoop 1.x配置的以下内容 不要删除 !!!
<!-- 一定要有,不然后面运行yarn时,container会应为找不到文件而启动失败,因为hadoop.tmp.dir默认为/tmp -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/bigdata/hadoop/ha</value>
</property>4. 配置slaves
其中配置的为datanode (hadoop 1.x配置了就不要配置了)
vi slaves 添加
node02
node03
node045. 复制到其他节点
cd /opt/devel/hadoop-2.6.5/etc/hadoop/
scp ./* node02:`pwd`
scp ./* node03:`pwd`
scp ./* node04:`pwd`启动
严格按顺序来
cd /opt/devel/hadoop-2.6.5/sbin(1)、在node02、03、04启动qjournalnode集群节点
./hadoop-daemon.sh start journalnode(2)、先再一个namenode节点上(例如node01)格式化
(格式化前记得删除 hdfs.tmp.dir目录)
hdfs namenode -format(3)、然后 先启动 这个namenode节点
(必须先启动,不然node02同步格式化时会报错 FATAL ha.BootstrapStandby, node01进程没有启动怎么复制?)
./hadoop-daemon.sh start namenode(4)、同步格式化 至另一个namenode: node02,node02上运行
hdfs namenode -bootstrapStandby(5)、在node01,02,03 先启动zookeeper
(必须先启动,不然会格式化会报refused connection的错误,因为是hadoop通过rpc端口操作的zk的)
zk节点上各自运行
cd /opt/devel/zookeeper/bin/
./zkServer.sh start(6)、格式化zookeeper
(在一个namenode节点上,例node01上运行命令,所有zk节点都会格式化)
hdfs zkfc -formatZK(7)、 启动hdfs
自动启动(自动启动按顺序启动 namenode, datanode, qjournalnode, zkfc)
cd /opt/devel/hadoop-2.6.5/sbin
./start-dfs.sh 手动挨个启动
hadoop/sbin/hadoop-daemon.sh start|stop namenode|datanode|zkfc|journalnode报错
如果hdfs创建目录文件时报错 Operation category READ is not supported in state standby
首先在处于 standby 状态的namenode是不能处理文件的
如果两个namenode都不能创建,那可能两个都处于standby状态
(1)、 我们这里是集群开启了自动故障切换(即 hdfs-site.xml 中设置了
dfs.ha.automatic-failover.enabled 为 true ) 而启用了ZKFC做自动失效恢复的状态下是不允许修改的,只能通过强制切换 --forcemanual
、手动强制启动至active状态
hdfs haadmin -transitionToActive --forcemanual nn1 强制切换之后ZKFCj将停止工作,之后不会有自动故障切换的保障,这时在各个nn上重新启动ZKFC就好了
./hadoop-daemon.sh start zkfc(2)、如果集群没有开启自动故障切换(即 hdfs-site.xml 中设置了
dfs.ha.automatic-failover.enabled 为 false ) 则可以通过下面方法对NameNode的状态进行安全的切换,其中后面一个会变为active状态
hdfs haadmin -failover --forcemanual serviceId serviceId2如果zkfc logs里报 FATAL org.apache.hadoop.ha.ZKFailoverController: Unable to start failover controller.Parent znode does not exist. Run with -formatZK flag to initialize ZooKeeper.
将dfs和zookeeper停止后,/opt/zookeeper目录删除 重新写好myid文件
再重新格式化zookeeper
hdfs zkfc -formatZK测试
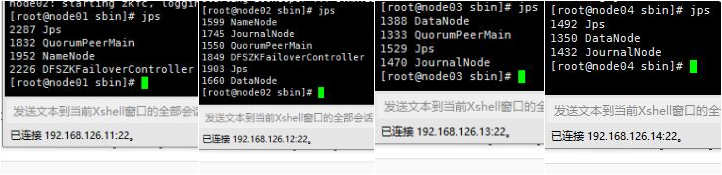
首先jps查看各个节点的进程是否启动
网页端口为 50070
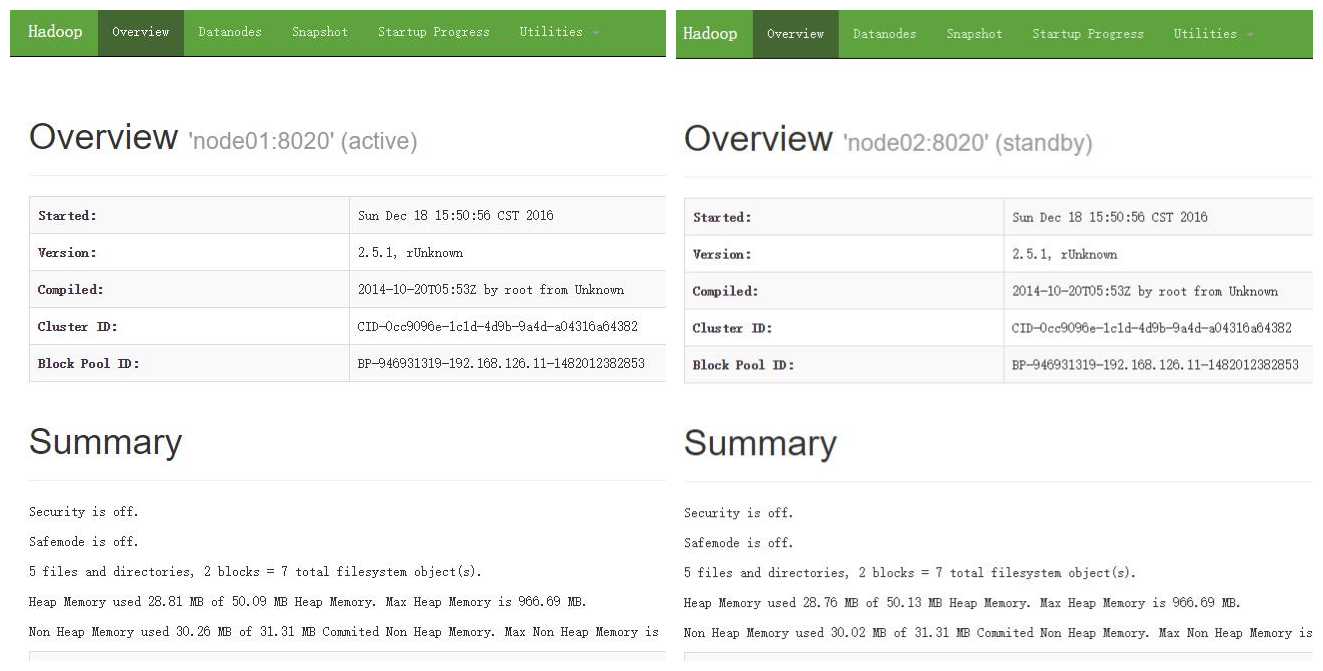
手动关闭一个namenode节点看standby换为active
./hadoop-daemin.sh stop namenode如果失败查看日志
配置总结
hdfs问题
NN单点故障 ——> HA
NN内存受限 ——>联邦
1、成功条件
元数据信息完全一致
NN1 fsimage 格式化后 采取同步格式化至NN2 使之一致
edits由jns集群管理保持一致 fsimage\edits 合并交由 standby NN 做 (1.x 由 snn 做)
zookeeper (当NN等节点出问题时 zookeepe "自动切换NN“ active )
zkfc节点监控当前nn运行的健康状态,通过心跳汇报zookeeper
监控NN的active和standby状态,宕机时切换
2:细节 Jns >= 3 奇数个
zk >=3 奇数个
3:部署:两个NN 都要免密钥
文件夹:hadoop.tmp.dir dfs.namenode.edits.dir(即dfs.namenode.name.dir)都要为空,删除之
zookeeper
zoo.cfg:
dataDir server.x=zoox:2888:3888
myid=1|2|3(每个zookeeper集群节点写自己的id)
hadoop
hdfs-site.xml nameservice 修改为自己设置的名称
core-site.xml fs.defaultFS
4:操作
1:首先Jns 每台jns启动
2:找一台NN执行格式化,执行同步,至其他NN 保证fsimage文件一致
3:启动zk集群 格式化zk
5: 启动hdfs