Hadoop核心组件——MR
Hadoop分布式计算框架(MapReduce)
何为MapReuce,一个例子
你想数出一摞牌中有多少张黑桃。直观方式是一张一张检查并且数出有多少张是黑桃。
MapReduce方法则是:
1.给在座的所有玩家中分配这摞牌
2.让每个玩家数自己手中的牌有几张是黑桃,然后把这个数目汇报给你
3.你把所有玩家告诉你的数字加起来,得到最后的结论
MapReduce设计理念
分布式计算
移动计算,而不是移动数据
Map-reduce的思想就是“分而治之”
Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”执行
“简单的任务”有几个含义:
数据或计算规模相对于原任务要大大缩小;
就近计算,即会被分配到存放了所需数据的节点进行计算;
这些小任务可以并行计算,彼此间几乎没有依赖关系;
Mapreduce初析
Mapreduce是一个计算框架,
既然是做计算的框架,那么表现形式就是有个输入(input),mapreduce操作这个输入(input),
通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。
Input——>MapReduce——>HDFS
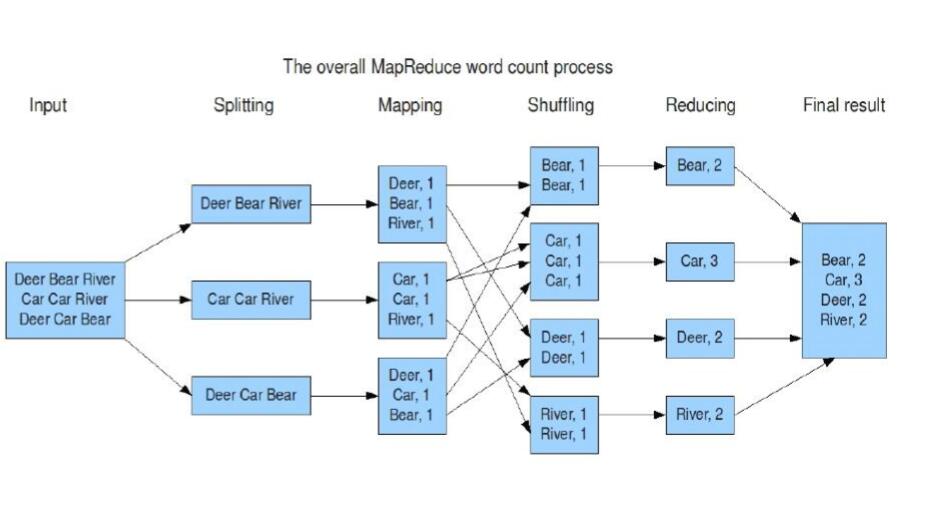
单词统计例子
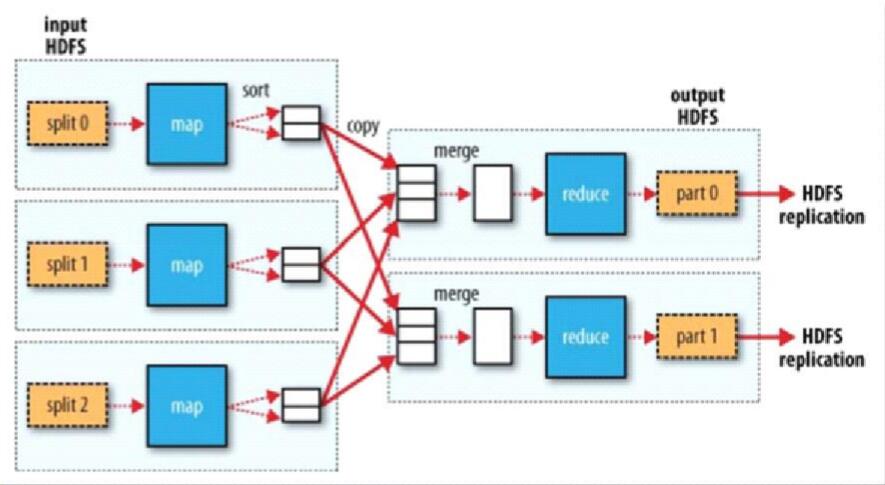
MapReduce运行机制,按照时间顺序包括:
输入分片(input split)、map阶段、shuffle阶段和reduce阶段。
1、输入分片(input split)
在进行map计算之前,mapreduce会在客户端根据程序里设置的输入路径,获取该路径下的文件及各个文件的block位置信息
mapreduce会根据输入文件计算输入分片个数与大小,
每个输入分片针对一个map任务,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
划分Split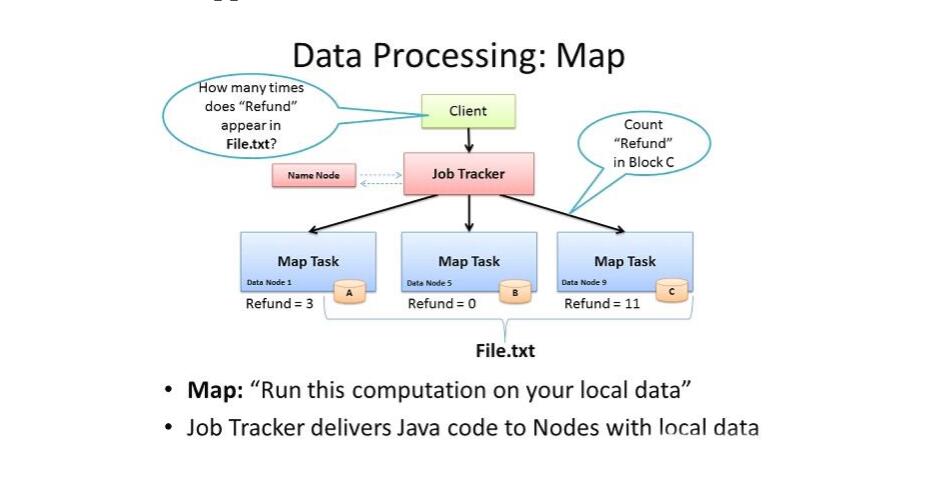

max.split(默认Long.MaxValue),min.split(默认1),block(64M , 2.下)
根据设置可得出每个分片大小,上述设置可得
max(min.split,min(max.split,block))
然后根据切片大小,对每个文件划分split , (记录每个split对应的偏移量)
如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片,65mb则是两个输入分片,而127mb也是两个输入分片。
分发MapTask
上面获取了map计算的单位 split,split可能由多个block组成, 前面获取的信息也包括了每个block块的位置,这样map reduce就会直到这个split的数据对应的数据主要在哪个节点上,然后每个split就会分发maptask到对应的节点上。
2、map阶段
mapTask个数由split决定,每个MapTask处理一个split的数据。
上面split阶段就知道了这个MapTask的对应的block块,这个map就会根据传过来的偏移量offset,通过hdfsAPI,对hdfs文件做 fileinput.seek(offset) 读取,这样本地的block文件就不需要传输,其他节点剩下的部分,就会通过网络传输拉取到这个节点。
然后MapTask就会通过 一行一行的读取 这个split的数据,程序员自己编写的map函数处理,然后再以以键值对输出。
3、shuffle阶段
在mapper和reducer中间的一个步骤,将map的输出作为reduce的输入的过程就是shuffle了.
Shuffle Write阶段 (Map节点上):
MapTask Context.Write 时 , 会将写的这行数据序列化先写到缓存数组中 (Buffer环中),
而写之前会根据 分区器Partitioner 计算出这行数据对应的分区号 :
分区数由ReduceTask个数决定,默认时HashPartitioner , 可自定义
根据 这行数据的Key对分区数取模 (key的hash值%上reduce的个数)
随着越来越多的数据写入Buffer环 (最大:100M)中,当达到阈值 ,环的大小的 0.8 时: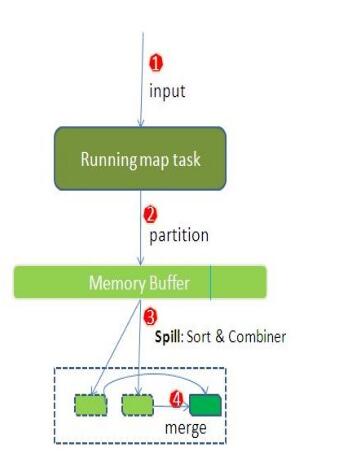
会启动一个Spill线程进行溢写,将数据写到磁盘
溢写的同时,会锁住这80%的内存,即MapTask只能往剩下的20%内存写数据
每次溢写的同时,会对这次溢写的数据进行排序:
先根据前面算出的分区号将同一个分区的放在一起,再根据排序比较器对一个分区内的数据进行排序,排序方法为快排
如果设置自定义排序比较器 sortComparator,则按自定义的排序,如果没有则默认是 KeyComparator 即按照Key排序 ,Key为String,按字符排序,Key为int,按照数值排序。
排序完成后溢写到磁盘,每次溢写生成一个小文件
每溢写 3 次会触发一个 Combiner 操作
combiner等同与在Map端的一种reduce操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作。
来减小Reduce聚合的负担,但是前提的Reduce里的计算逻辑能支持在Map端执行Combiner。
默认没有设置Combiner,如果没有设置,就不会进行Combiner。
待MapTask将所有的数据处理完成后,会将Buffer环触发Flush,将所有数据溢写到磁盘。
这时小文件达到最小spill文件数3 ,也会进行一次Combiner。
然后MapReduce会将所有小文件进行Merge合并,合并成一个大文件,等待Reduce拉取:
合并时将相同的分区的合并在一起,分区内进行归并排序。
记录下每个分区在合并后的这个大文件中的偏移量
Shuffle Read阶段 (Reduce节点上):
每个ReadTask会去Map端去拉取属于自己处理的分区数据,根据前面的偏移量去每个Map端拉取对应大文件中某段
多少个MapTask就会拉取会多少个文件。
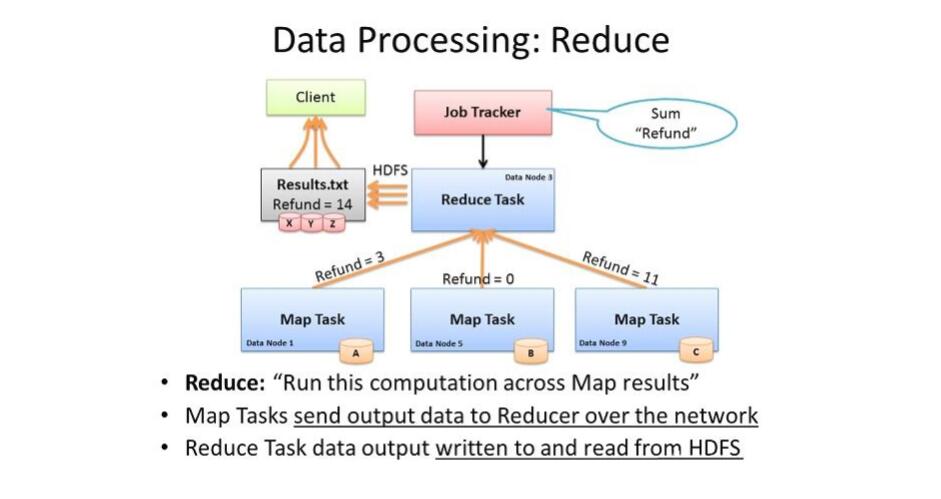
4、reduce阶段
前面将各个MapTask的结果文件中属于自己的拉取到对应的Reduce端
然后进行归并排序合并这些文件,在返回一个逻辑迭代器来迭代这批数据(这时数据可能在磁盘,少部分可能在内存)
代码中每执行一个Reduce函数,就是处理一个组的数据:
MapReduce是根据分组比较器groupComparator来判断数据是否为一组的,(并不是一个组内Key都是相同的)
判断过程是每遍历一行,用分组比较器判断是否为一组Key,是则继续遍历,不是则下一行为另外一组的Key,再去遍历下一组
也就是分在一组的的数据在文件中必须连续的排序一起,而排序的是在文件合并时根据 排序比较器sortComparator 排序的
也就是 groupComparator 与 sortComparator中的排序逻辑必须不冲突,groupComparator 应该包含sortComparator
处理完后context.write写入磁盘
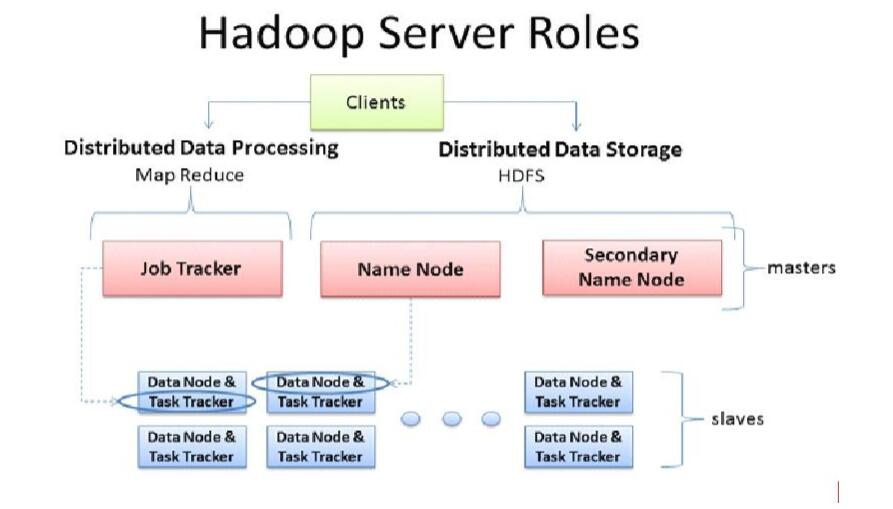
MapReduce的架构(Hadoop 1.x)
主多从架构
主 JobTracker
负责调度分配每一个子任务task运行于TaskTracker上,
如果发现有失败的 task就重新分配其任务到其他节点。
每一个hadoop集群中只一个JobTracker, 一般它运行在Master节点上,监控整个集群的资源负载
从 TaskTracker
TaskTracker 主动 与JobTracker通信,接收作业,并负责直接执行每一个任务 ,
为了减少网络带宽TaskTracker最好运行在HDFS的DataNode上,数据本地化。
Client
作业为单位,规划作业计算分布,提交作业资源到HDFS
最终提交作业到JobTracker
架构图
弊端:
JobTracker:负载过重,单点故障
资源管理与计算调度强耦合,其他计算框架需要重复实现资源管理
不同框架对资源不能全局管理