hdps 完全分布式安装(hadoop 1.x)
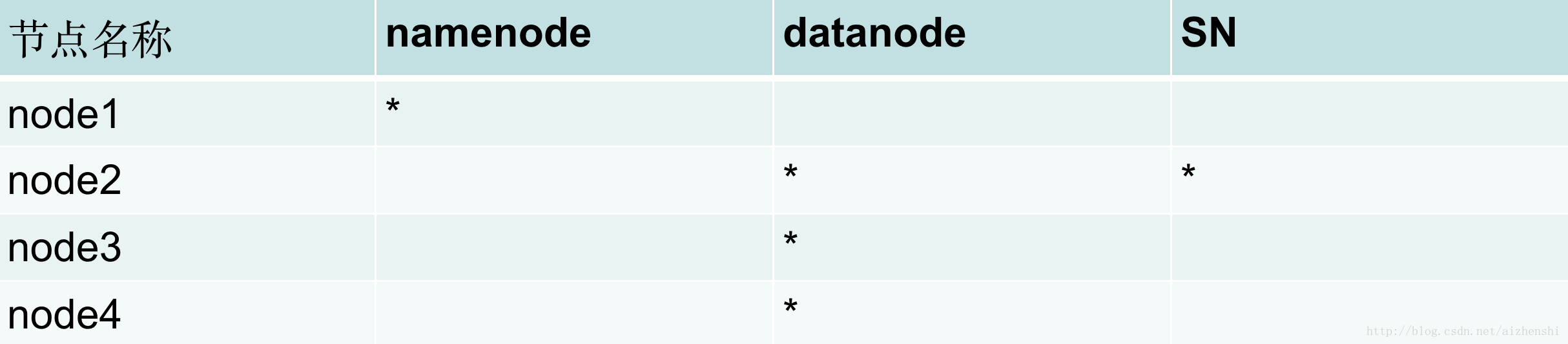
节点图
测试环境:CentOS 6.5
1、装备:网络 hosts(192.168.126.11 node01 等) 防火墙关闭
2、时间同步
4个节点运行(找了半天202.120.2.101就个能行)
ntpdate 202.120.2.101 ntpdate需安装ntp
yum install ntp -y3、ssh免密钥(namenode需要免密钥登陆到datanode)
namenode (node01)上
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keysssh-keygen这个命令会产生一个公钥(~/.ssh/id_dsa.pub)和密钥(~/.ssh/id_dsa),
-t dsa:表示使用密钥的加密类型,可以为'rsa'和'dsa'
-P '':表示不需要密码登录
-f ~/.ssh/id_dsa:表示密钥存放的路径为${USER}/.ssh/id_dsa
复制到其他节点上
scp ~/.ssh/id_dsa.pub root@192.168.126.14:/root/download其他node(node02,03,04)上
因为~/.ssh 默认没有 通过以下ssh-keygen命令生成 或者手动创建~/.ssh/authorized_keys
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat /root/download/id_dsa.pub >> ~/.ssh/authorized_keys#非root用户需要设置 .ssh 和 authorized_keys 的权限
#linux认对这些文件设置组权限是 bad auth
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
#去掉组成员的权限tar xf hadoop.tar.gz -C /opt/devel/安装jdk
配置hadoop环境变量 /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_PREFIX=/opt/devel/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin/opt/devel/hadoop-2.6.5/etc/hadoop/hadoop-env.sh
/opt/devel/hadoop-2.6.5/etc/hadoop/slaves
/opt/devel/hadoop-2.6.5/etc/hadoop/core-site.xml
/opt/devel/hadoop-2.6.5/etc/hadoop/hdfs-site.xml
hadoop-env.sh
该文件是hadoop运行基本环境的配置,需要修改的为java虚拟机的位置。
export JAVA_HOME=/usr/java/jdk1.7.0_67slaves和masters
hadoop的集群是基于master/slave模式,namenode和jobtracker属于master,datanode和tasktracker属于slave,master只有一个,而slave有多个
分布式存储(hdfs)角度:集群中的节点由一个namenode和多个datanode组成。namenode是中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据库,这些块存储在一组datanode上。 namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体datanode节点的映射。datanode负责处理文件系统客户端的读写请求。在namenode的统一调度下进行数据块的创建、删除和复制。
分布式应用(mapreduce)角度:集群中的节点有一个jobtracker和多个tasktracker组成。jobtracker负责任务的调度,tasktracker负责并行执行任务。tasktracker必须运行在datanode上,这样便于数据的本地计算,而jobtracker和namenode则必须在同一台机器上。
vi slaves输入
node02
node03
node04core-site.xml
这个是hadoop的核心配置文件,这里需要配置的就这两个属性,
fs.default.name 配置了hadoop的HDFS系统的命名,位置为主机的9000端口;
hadoop.tmp.dir 配置了hadoop的tmp目录的根位置。这里使用了一个文件系统中没有的位置,所以要先用mkdir命令新建一下
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/bigdata/hadoop/full</value>
</property>
</configuration>hdfs-site.xml
这个是hdfs的配置文件,
dfs.namenode.secondary.http-address 配置secondary node 位置
dfs.replication 配置了文件块的副本数,一般不大于从机的个数。如果是配置伪分布式的话,副本数一定要设为1
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>node02:50090</value> </property><property> <name>dfs.replication</name> <value>3</value> </property></configuration>
同步所有配置文件
cd /opt/devel/hadoop-2.6.5/etc/hadoop/
scp ./* root@192.168.126.12:`pwd`
scp ./* root@192.168.126.13:`pwd`
scp ./* root@192.168.126.14:`pwd`格式化
hdfs namenode -format启动
start-dfs.sh测试
jps
hadoop dfs -mkdir -p /user/root
hadopp dfs -put /root/up.txt /file
hadoop dfs -get /file/up.txt
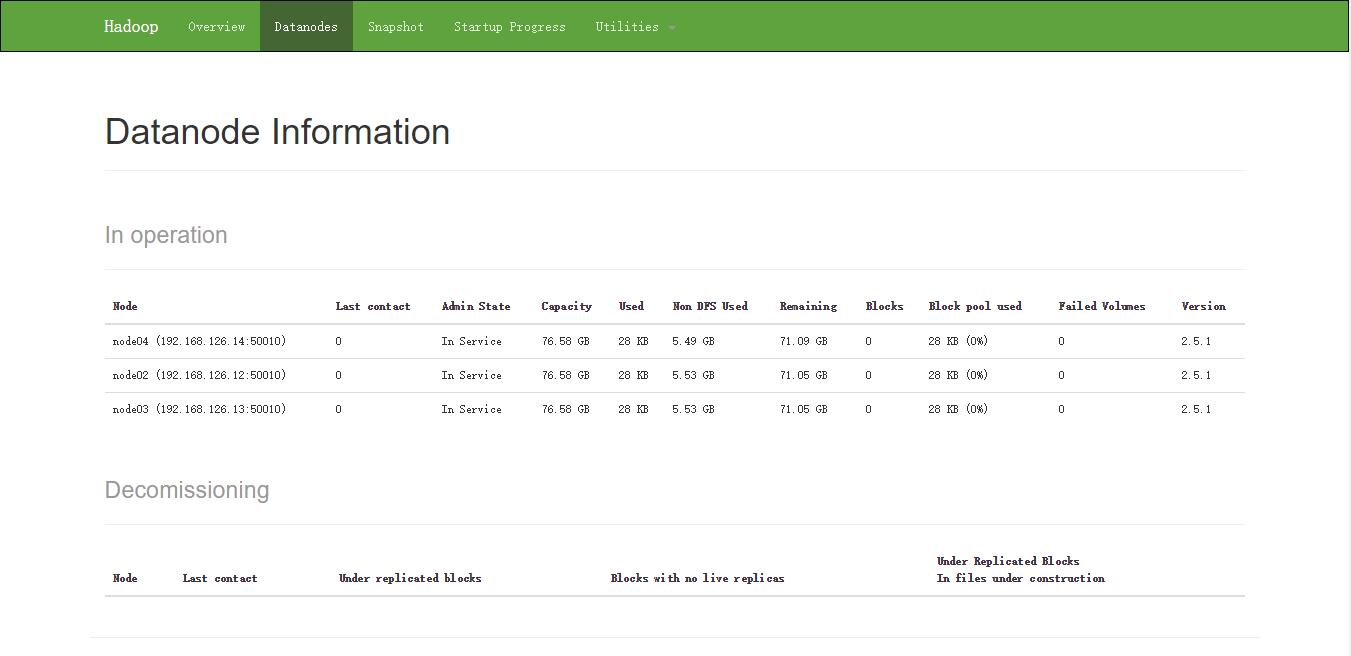
hadoop dfs -ls /file网页查看
如果是要配置单机的伪分布式的话
就把namenode,secondary-namenode,slaves指定为同一节点,dfs.replication副本数一定要设为1.