理解关联规则
• 市场购物篮分析的结果是一组指定商品之间关系模式的关联规则。
• 一个典型的规则可以表述为: 奶爸去买尿不湿会顺便买啤酒,而且这个规则是有顺序的
• 关联规则用通俗易懂的语言来表达就是:
如果有规则{花生酱,果冻} —> {面包},如果购买了花生酱和果冻,那么也很有可能会购买面包。
支持度和置信度
• 支持度 (support) 是指 一个项集 在数据中出现的频率
• 置信度 (confidence) 是指 一个规则 的 预测能力(准确度的度量)
公式:
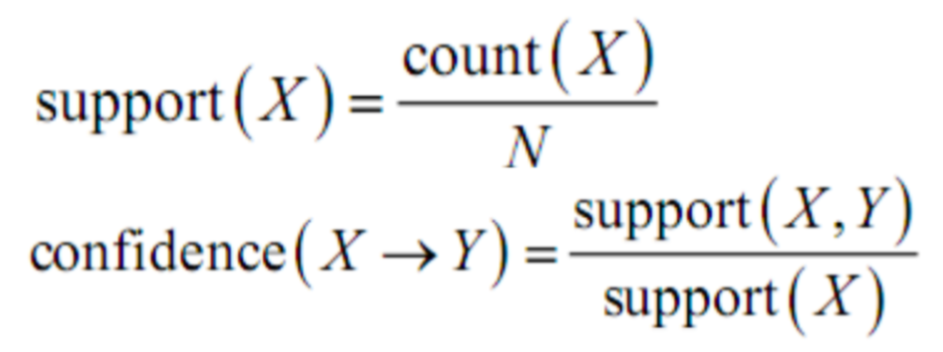
数据:
| 交易号 | 购买的商品 |
| 1 | {鲜花,慰问卡,苏打水} |
| 2 | {毛绒玩具熊,鲜花,气球,单独包装的块状糖} |
| 3 | {慰问卡,单独包装的块状糖,鲜花} |
| 4 | {毛绒玩具熊,气球,苏打水} |
| 5 | {鲜花,慰问卡,苏打水} |
求规则:{鲜花} —> {慰问卡} 的置信度 ?
{鲜花} 的支持度 = 4/5 , {鲜花,慰问卡} 的支持度 = 3/5
所以 {鲜花} —> {慰问卡} 的置信度 为 (3/5)/ (4/5) = 3/4
理解Apriori算法
• Apriori算法原则 指的是一个频繁项集的所有子集也必须是频繁的。(频繁即项集支持度高)
即如果{A,B}是频繁的,那么{A}和{B}都必须是频繁的。
因为根据定义,支持度表示一个项集出现在数据中的频率。因此,如果知道{A}不满足所期望的支持度阈值,那么就没有考虑{A,B}或者任何包含{A}的项集,这些项集绝对不可能是频繁的。
• Apriori算法利用这个逻辑在实际评估他们之前排除潜在的关联规则 ,即首先排除掉单个项集不满足支持度的,让它们不参与接下来的组合
• 排除之后又分为 两个阶段:
1、将数据组合成各种项集,然后识别所有满足最小支持度阈值的项集 (排除掉不满足支持度的项集)
2、根据这些项集来创建各种关联规则,然后 根据最小置信度阈值评估排除规则
例如,{A,B,C}将产生候选规则{A}->{B}、{A}->{C}、{B}->{C}、{B}->{A}、{C}->{A}、{C}->{B}
这些规则将根据最小置信度阈值评估,任何不满足所期望的置信度的规则将被排除。
例子:
每一个顾客的购物车买的东西,求哪些物品有对某一个有关联关系
数据:
代码:
#csv文件以,间隔
#这里是将每个单元格作为一行
#read.transactions为arules包方法,需先安装再导入
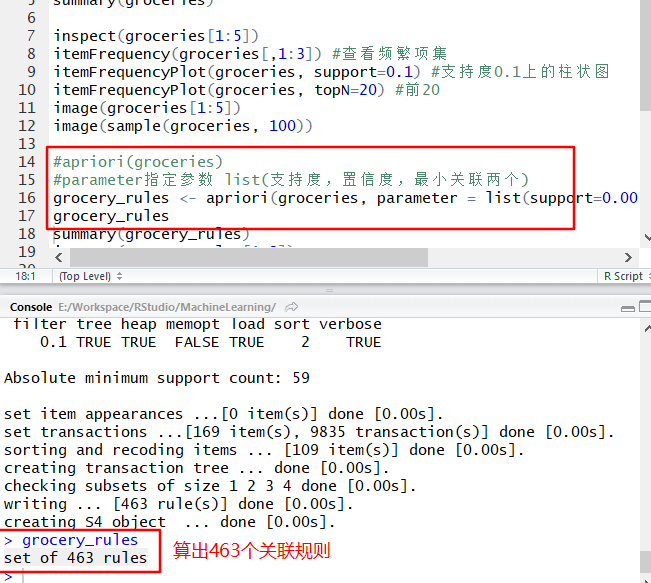
groceries <- read.transactions("AssociationRules/data/groceries.csv", sep=",")
summary(groceries)inspect(groceries[1:5])
itemFrequency(groceries[,1:3]) #查看频繁项集
itemFrequencyPlot(groceries, support=0.1) #支持度0.1上的柱状图
itemFrequencyPlot(groceries, topN=20) #前20
image(groceries[1:5])
image(sample(groceries, 100))#apriori(groceries)
#parameter指定参数 list(支持度,置信度,最小关联两个)
grocery_rules <- apriori(groceries, parameter = list(support=0.006, confidence=0.25, minlen=2))
grocery_rules
#概要 lift为support、confidence合在一起的参数,越大越关联
summary(grocery_rules)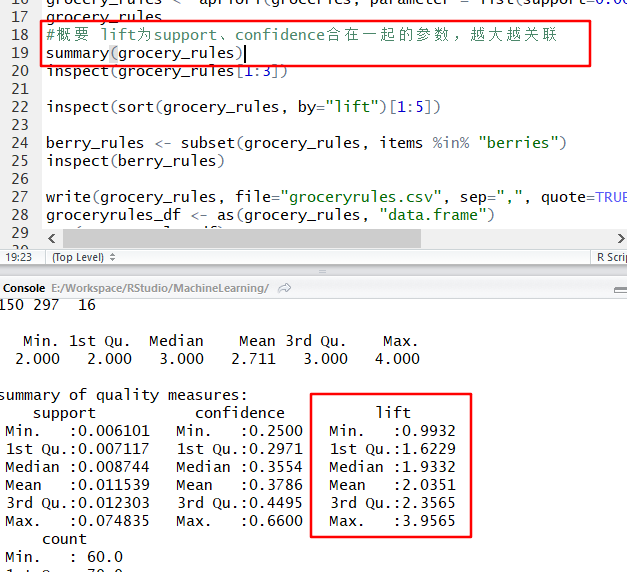
#查看关联前三个
inspect(grocery_rules[1:3])
#以lift排序,再查看前5
inspect(sort(grocery_rules, by="lift")[1:5])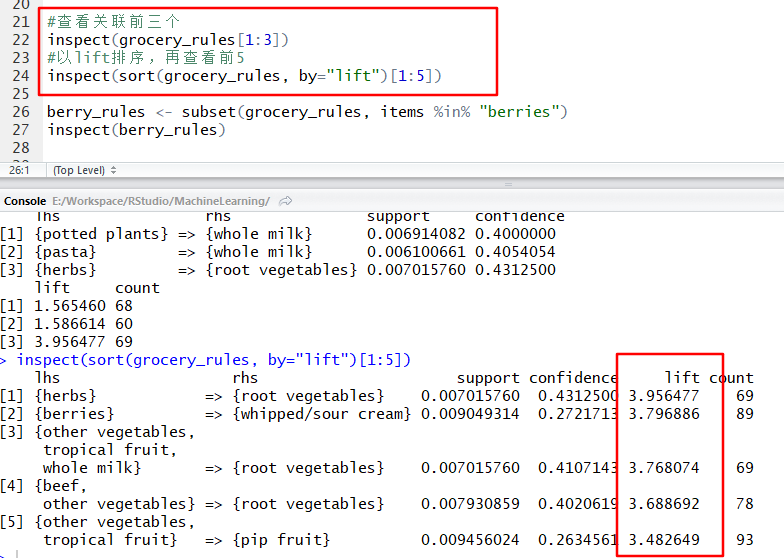
完整代码:
#csv文件以,间隔
#这里是将每个单元格作为一行
#read.transactions为arules包方法,需先安装再导入
groceries <- read.transactions("AssociationRules/data/groceries.csv", sep=",")
summary(groceries)
inspect(groceries[1:5])
itemFrequency(groceries[,1:3]) #查看频繁项集
itemFrequencyPlot(groceries, support=0.1) #支持度0.1上的柱状图
itemFrequencyPlot(groceries, topN=20) #前20
image(groceries[1:5])
image(sample(groceries, 100))
#apriori(groceries)
#parameter指定参数 list(支持度,置信度,最小关联两个)
grocery_rules <- apriori(groceries, parameter = list(support=0.006, confidence=0.25, minlen=2))
grocery_rules
#概要 lift为support、confidence合在一起的参数,越大越关联
summary(grocery_rules)
#查看关联前三个
inspect(grocery_rules[1:3])
#以lift排序,再查看前5
inspect(sort(grocery_rules, by="lift")[1:5])
#Subset函数第一个参数是所要选择的数据框,第二个参数是所要查看信息的方法
berry_rules <- subset(grocery_rules, items %in% "berries")
inspect(berry_rules)
#写入文件
write(grocery_rules, file="AssociationRules/output/groceryrules.csv", sep=",", quote=TRUE, row.names = FALSE)
#转为dataframe
groceryrules_df <- as(grocery_rules, "data.frame")
str(groceryrules_df)