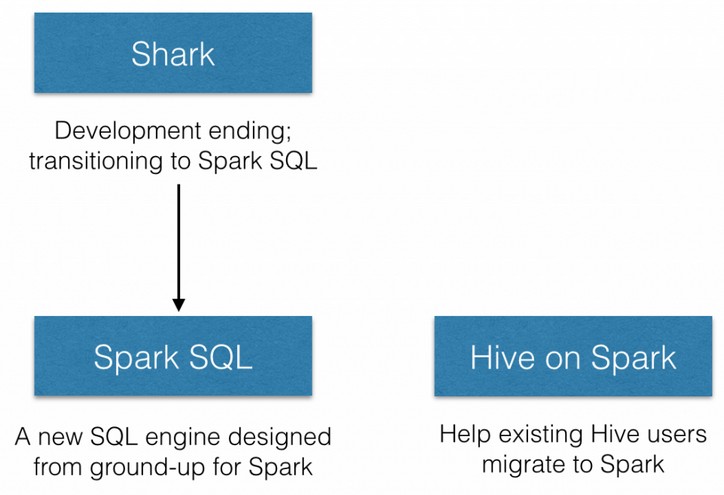
SparkSQL前身 Shark
基于MapReduce的SQL执行引擎是Hive,而Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,
由于底层的计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,当数据全部load在内存的话,将快10倍以上,
因此Shark可以作为交互式查询应用服务来使用。除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上,Shark底层依赖于Hive的解析器,查询优化器。
但正是由于SHark的整体设计架构对Hive的依赖性太强,难以支持其长远发展,比如不能和Spark的其他组件进行很好的集成,无法满足Spark的一栈式解决大数据处理的需求。
2、Spark on Hive和Hive on Spark
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行计算。
Hive on Spark:Hive即作为存储又负责sql的解析优化(使用HiveSQL解析器),Spark负责执行计算。Hive 2.X支持Hive on Spark
3、DataFrame分布式数据框

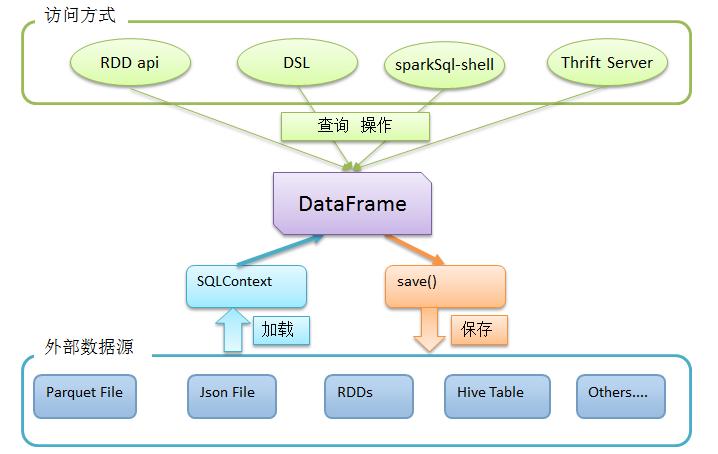
DataFrame 也是一个分布式数据框(容器)。与RDD类似,然而DataFrame更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。
从API易用性的角度上 看, DataFrame API提供的是一套高层的关系操作(即SQL操作),比函数式的RDD API要更加友好,门槛更低。
DataFrame的底层是一个个的RDD,只不过 RDD的泛型是Row类型 。DataFrame = RDD<Row>
一般来说,都是优先使用DataFrames而不直接使用RDD,因为DataFrames会优化你的执行计划,而RDD则是忠实的按照你代码生成执行计划,并且spark sql 中提供很多方法便利地从多种数据源生成DataFrames。
二、创建DF的方式
或者说SparkSQL能够接受的数据源
首先
Spark SQL 有一个自己的上下文 SQLContext,对于集群的操作需要通过次上下文
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);1、json格式的文件
spark会自动推测 列名,注册成临时表时,表中的列默认按ascii顺序显示列。
不能使嵌套格式的json,也就是 {} 里不能有 {}
DataFrame df = sqlContext.read().json("people.json");与
DataFrame df = sqlContext.read().format("json").load("people.json");df.registerTempTable("p"); //注册成临时表
2、json格式的RDD
创建一个 RDD<String> 类型的RDD,其中 String 为 json 格式 字符串
再通过 sqlContext.read().json( rdd ) 方法得到 DataFrame
List<String> scoreList = Arrays.asList(
"{'name':'zhangsan','score':100}",
"{'name':'lisi','score':99}" );
JavaRDD<String> scoreRDD = sc.parallelize(scoreList);
DataFrame scoreDF = sqlContext.read().json(scoreRDD);3、parquet格式文件
读取parquet文件会自动推测分区: 即路径指定一个文件夹,会将 key=value 格式的文件夹,会将 列作为key
DataFrame usersDF = sqlContext.read().format("parquet").load("users.parquet");导出parquet格式文件
SaveMode指定文件保存时的模式。
resultDF.write().format("json").mode(SaveMode.Ignore).save("result.json"); // SaveMode.Overwrite
resultDF.write().format("json").save("result.json");4、普通的RDD转成DF
① 反射
对一个RDD,通过传入的自定义类的字段生成schema,创建dataframe
自定义类注意点:
类与字段修饰符 public
实现序列化 Serializable 接口
public class Person implements Serializable{
private Integer id;
private String name;
private Integer age;
.....JavaRDD<String> lines = sc.textFile("Peoples.txt");
JavaRDD<Person> personsRdd = lines.map(new Function<String, Person>() {
@Override
public Person call(String line) throws Exception {
String[] split = line.split(",");
Person p = new Person();
p.setId(Integer.valueOf(split[0].trim()));
p.setName(split[1]);
p.setAge(Integer.valueOf(split[2].trim()));
return p;
}
});
//传入进去Person.class的时候,sqlContext是通过反射的方式创建DataFrame
//在底层通过反射的方式或得Person的所有field,结合RDD本身,就生成了DataFrame
DataFrame df = sqlcontext.createDataFrame(personsRdd, Person.class);dataFrame 转 rdd<row>
这是要注意在 Java 中 row.getInt(index) , index跟person类中 字段的定义顺序 无关 ,而是 字段按ascii码排序 的顺序。
scala 中,则 index 跟 person类中 字段的定义顺序 一致
推荐使用 row.getAs(filedName)
// dataFrame to rdd
JavaRDD<Row> rdd = resultDataFrame.javaRDD();
JavaRDD<Person> pRdd = rdd.map(new Function<Row, Person>() {
private static final long serialVersionUID = 1L;
@Override
public Person call(Row row) throws Exception {
int age = row.getInt(0);
int id = row.getInt(1);
String name = row.getString(2);
// String name = row.getAs("name")
Person person = new Person(id, name, age);
return person;
}
});反射的Scala代码:
val conf = new SparkConf()
conf.setMaster("local").setAppName("rddreflect")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val lineRDD = sc.textFile("./sparksql/person.txt")
/**
* 将RDD隐式转换成DataFrame
*/
import sqlContext.implicits._
val personRDD = lineRDD.map { x =>{
val person = Person(x.split(",")(0),x.split(",")(1),Integer.valueOf(x.split(",")(2)))
person
}
}
val df = personRDD.toDF(); // RDD隐式转换成DataFrame
df.show()
/**
* 将DataFrame转换成PersonRDD
*/
val rdd = df.rdd
val result = rdd.map { x => {
Person(x.getAs("id"),x.getAs("name"),x.getAs("age"))
}
}
result.foreach { println}
sc.stop()
② 动态创建schema的方式
在RDD的基础上创建类型为Row的RDD
动态构造DataFrame的元数据,用于构建StructType(DataFrame元数据的描述)
基于已有的MetaData以及RDD<Row> 调用 createDataFrame(rowRDD : RDD[Row], schema : StructType) 来构造DataFrame
一般而言,有多少列以及每列的具体类型可能来自于Json,也可能来自于DB(将schema存储在数据库)
动态创建比反射常用,因为dataframe的schema会经常变换,动态创建更灵活
SQLContext sqlcontext = new SQLContext(sc);
/**
* 在RDD的基础上创建类型为Row的RDD
*/
JavaRDD<String> lines = sc.textFile("Peoples.txt");
JavaRDD<Row> rowRDD = lines.map(new Function<String, Row>() {
@Override
public Row call(String line) throws Exception {
String[] split = line.split(",");
return RowFactory.create(Integer.valueOf(split[0]),split[1],Integer.valueOf(split[2]));
}
});
/**
* 动态构造DataFrame的元数据,一般而言,有多少列以及每列的具体类型可能来自于Json,也可能来自于DB
*/
ArrayList<StructField> structFields = new ArrayList<StructField>();
structFields.add(DataTypes.createStructField("id", DataTypes.IntegerType, true));
structFields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
structFields.add(DataTypes.createStructField("age", DataTypes.IntegerType, true));
//构建StructType,用于最后DataFrame元数据的描述
StructType schema = DataTypes.createStructType(structFields);
/**
* 基于已有的MetaData以及RDD<Row> 来构造DataFrame
*/
DataFrame df = sqlcontext.createDataFrame(rowRDD, schema);row.getInt(index),索引依据于 structFields 中 structField 的添加顺序
5、SparkSQL读取 jdbc 中的数据
①、sqlContext.read().format("jdbc") .options(MapProperties).load();
Map<String, String> options = new HashMap<String, String>();
options.put("url", "jdbc:mysql://hadoop1:3306/testdb");
options.put("driver", "com.mysql.jdbc.Driver");
options.put("user","spark");
options.put("password", "spark2016");
options.put("dbtable", "student_info");
DataFrame studentInfosDF = sqlContext.read().format("jdbc").options(options).load();
options.put("dbtable", "student_score");
DataFrame studentScoresDF = sqlContext.read().format("jdbc") .options(options).load();②、sqlContext.read().format("jdbc") .options(PropertyName, PropertyValue).load();
DataFrameReader reader = sqlContext.read().format("jdbc");
reader.option("url", "jdbc:mysql://hadoop1:3306/testdb");
reader.option("dbtable", "student_info");
reader.option("driver", "com.mysql.jdbc.Driver");
reader.option("user", "spark");
reader.option("password", "spark2016");
DataFrame studentInfosDF = reader.load();
reader.option("dbtable", "student_score");
DataFrame studentScoresDF = reader.load();6、SparkSQL读取hive中的数据
Spark on Hive 配置
1. 在Spark客户端安装包下 spark-1.6.0/conf 中创建文件 hive-site.xml: 配置hive的metastore路径
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>2. 启动Hive的metastore服务
hive --service metastore start3. 启动zookeeper集群,启动HDFS集群
4. 启动SparkShell 读取Hive中的表总数,对比hive中查询同一表查询总数测试时间。
./spark-shell import org.apache.spark.sql.hive.HiveContext val hc = new HiveContext(sc) hc.sql("show databases").show hc.sql("user default").show hc.sql("select count(*) from jizhan").show
注意:
如果使用Spark on Hive 查询数据时,出现错误: 
找不到HDFS集群路径,要在客户端机器conf/spark-env.sh中设置 hadoop-conf 的路径:
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop 代码:
通过创建 HiveContext 对象 , 在通过 hiveContext.sql( hivesql ) 执行 hivesql
//HiveContext是SQLContext的子类。
SQLContext hiveContext = new HiveContext(sc);
//删除hive中的student_infos表
hiveContext.sql("DROP TABLE IF EXISTS student_infos");二、DataFrame的API
show
默认只是显示这个DF里面的前十行数据
show(numRows),指定行数
类似Spark core里面的action类算子
df.show();select
df.select("age").show();
//SELECT name,age+10 as plusAge FROM table;
df.select(df.col("name"),df.col("age").plus(10).as("plusAge")).show();filter
//SELECT * FROM p WHERE age > 10
df.filter(df.col("age").gt(10)).show();groupBy
//SELECT COUNT(*) FROM p GROUP BY age
df.groupBy(df.col("age")).count().show(); Join
/**
* SELECT nameTable.name,nameTable.age,scoreTable.score
* FROM nameTable JOIN nameTable ON (nameTable.name == scoreTable.name)
*/
nameDF.join(scoreDF, nameDF.col("name").$eq$eq$eq(scoreDF.col("name")))SQL
直接传入sql,需要先将DataFrame注册成一张临时表
registerTempTable(tableName)
/**
* 将DataFrame注册成一张临时表
* p这个表,会物化到磁盘吗? 这个表只是逻辑上的。
*/
df.registerTempTable("p");
sqlContext.sql("")
sqlContext.sql("SELECT * FROM p WHERE age > 10").show();Join例子:
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkSQLwithJoin");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlcontext = new SQLContext(sc);
DataFrame peopleDF = sqlcontext.read().json("student.json");
// 基于Json构建的DataFrame来注册临时表
peopleDF.registerTempTable("peopleTable");
// 查询出年龄大于xx的人
DataFrame peopleScore = sqlcontext.sql("select name,score from peopleTable where score > 70");
// 在DataFrame的基础上转化成RDD,通过Map操作计算出分数大于90的所有人的姓名
List<String> peopleList = peopleScore.javaRDD().map(new Function<Row, String>() {
@Override
public String call(Row row) throws Exception {
return row.getAs("name");
}
}).collect();
// 动态组拼出Json
List<String> peopleInfomation = new ArrayList<String>();
peopleInfomation.add("{\"name\":\"Michael\",\"age\":20}");
peopleInfomation.add("{\"name\":\"Andy\",\"age\":17}");
peopleInfomation.add("{\"name\":\"Justin\",\"age\":19}");
// 通过内容为Json的RDD来构造DataFrame
JavaRDD<String> peopleInfomationRDD = sc.parallelize(peopleInfomation);
DataFrame peopleInfomationDF = sqlcontext.read().json(peopleInfomationRDD);
peopleInfomationDF.registerTempTable("peopleInfomation");
String sql = "select name,age from peopleInfomation where name in (";
for (String string : peopleList) {
sql += "'" + string + "',";
}
sql = sql.substring(0, sql.length() - 1);
sql += ")";
DataFrame execellentNameAgeDF = sqlcontext.sql(sql);
JavaPairRDD<String, Tuple2<Integer, Integer>> resultRDD = peopleScore.javaRDD()
.mapToPair(new PairFunction<Row, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Row row) throws Exception {
// TODO Auto-generated method stub
return new Tuple2<String, Integer>(String.valueOf(row.getAs("name")),
Integer.valueOf(String.valueOf(row.getAs("score"))));
}
}).join(execellentNameAgeDF.javaRDD().mapToPair(new PairFunction<Row, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Row row) throws Exception {
return new Tuple2<String, Integer>(String.valueOf(row.getAs("name")),
Integer.valueOf(String.valueOf(row.getAs("age"))));
}
}));
JavaRDD<Row> resultRowRDD = resultRDD.map(new Function<Tuple2<String,Tuple2<Integer,Integer>>, Row>() {
@Override
public Row call(Tuple2<String, Tuple2<Integer, Integer>> tuple) throws Exception {
// TODO Auto-generated method stub
return RowFactory.create(tuple._1,tuple._2._1,tuple._2._2);
}
});
/**
* 动态构造DataFrame的元数据,一般而言,有多少列以及每列的具体类型可能来自于Json,也可能来自于DB
*/
ArrayList<StructField> structFields = new ArrayList<StructField>();
structFields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
structFields.add(DataTypes.createStructField("score", DataTypes.IntegerType, true));
structFields.add(DataTypes.createStructField("age", DataTypes.IntegerType, true));
//构建StructType,用于最后DataFrame元数据的描述
StructType structType = DataTypes.createStructType(structFields);
/**
* 基于已有的MetaData以及RDD<Row> 来构造DataFrame
*/
DataFrame df = sqlcontext.createDataFrame(resultRowRDD, structType);
df.show();
//方法2:直接在sql语句中join
DataFrame sql2 = sqlcontext.sql("select * from peopleTable,peopleInfomation where peopleInfomation.name = peopleTable.name and peopleTable.score>70");
sql2.show();
}三、算子
dataFrame也可以执行算子
执行 map、mapPartitions、flatMap 会返回 RDD<row>
dataFrame 转 rdd
JavaRDD<Row> rowRDD = df.rdd()
JavaRDD<Row> rowRDD = df. javaRDD()