Apache Spark™ is a fast and general engine for large-scale data processing. (大规模数据处理的快速与通用引擎)
Apache Spark is an open source cluster computing system that aims to make data analytics fast
both fast to run and fast to wrtie (旨在提高运行速度和代码书写速度)
1、什么是Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的 类Hadoop MapReduce 的通用并行计算框架——Spark,
拥有Hadoop MapReduce所具有的优点;
但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
2013年6月进入了Apache孵化器项目
The Berkeley Data Analytics Stack

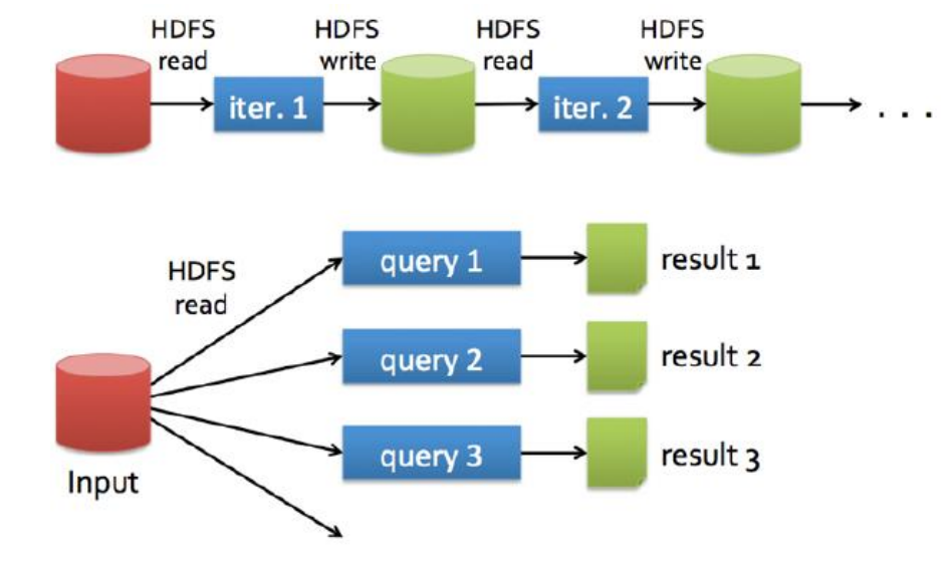
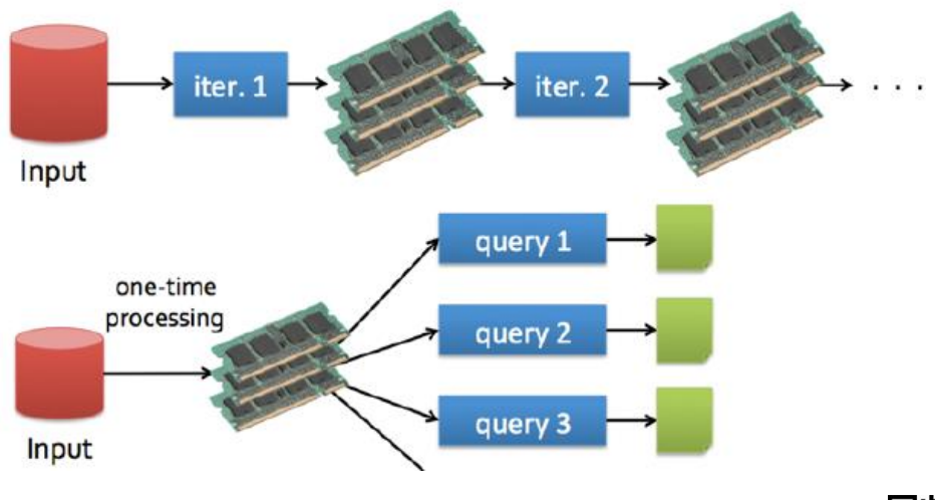
MapReduce VS Spark
官网:
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Apache Spark has an advanced DAG execution engine that supports acyclic data flow and in-memory computing.
Spark更快的原因:
1、Spark的每个Job计算结果可以放入到内存,支持每个Job基于内存迭代,MR根本不支持
2、Spark中有DAG有向无环图,可以实现pipeline的计算模式,将一个stage内作用一个分区上的task中算子连接起来
3、资源调度模式:Spark粗粒度的资源调度 MR是细粒度
Spark之所以能够跑到yarn上,是因为实现了ApplicationMaster接口
Spark是粗粒度的方式实现的,MR是细粒度实现的
资源复用角度:
Spark中所有的task可以复用同一批Executor资源
MR里面每一个map task对应一个JVM进程
运行模式
Local —— 多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone —— 不是字面上的意思,为Spark自带的资源管理框架,也可搭建完全分布式。
YARN —— Spark也是可以基于Yarn资源管理框架来计算的,最具前景 ,是用最多。
要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以
基于Yarn。
Mesos —— 开源分布式资源管理框架
2、spark任务执行原理
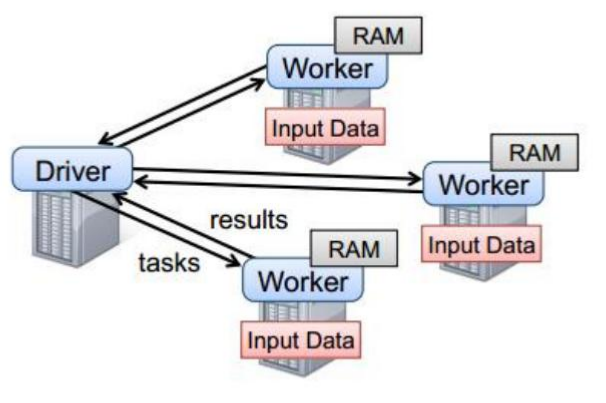
以上图中有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
Driver与集群节点之间有频繁的通信。
Driver负责任务(tasks)的分发和结果的回收。任务的调度。如果task的计算结果非常大就不要回收了。会造成oom。
Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM进程。
Master是Standalone资源调度框架里面资源管理的主节点。也是JVM进程。
Spark API
Scala —— 代码编写快速,执行速度跟Java相同,但可读性差
Java —— 代码编写慢,但可读性强
Python —— 代码编写快速,但执行效率慢,可读性差
R —— 编写简单,执行效率慢
RDD(Resilient Distributed Dataset )
弹性分布式数据集
Spark中代码中算子操作的单位(注意只是代码中),即算子时RDD类中的方法,算子的返回值也可以是RDD
五大特性:
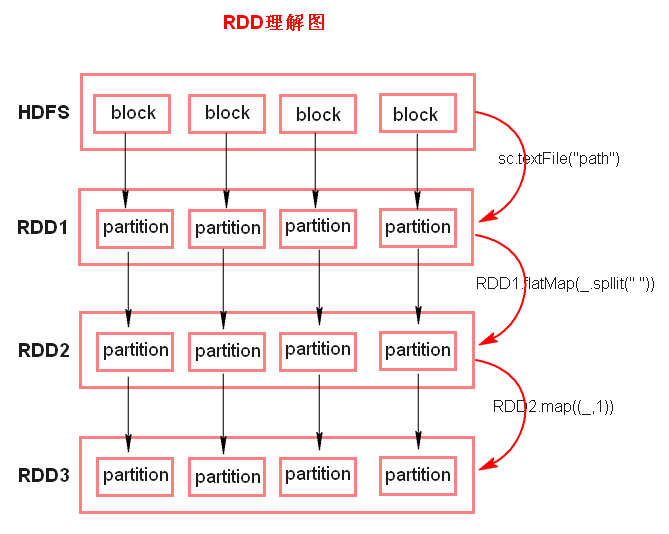
1、A list of partitions (RDD由一系列的分区组成)
每个partition 对应 hdfs的一个split,一个 split 不对应 一个block。
Spark 没有读 HDFS 的方法,它是引用 MapReduce 里的方法读的。
出了特殊的算子(如 ),父子RDD分区数相同。
RDD和Split均是逻辑上的概念,不存储数据。
2、A function for computing each partition (函数即算子作用在 每个分区 (不是RDD)上)
在每个分区上都有一个函数去迭代/执行/计算它。
3、A list of dependencies on other RDDs (每个RDD都有一系列的依赖)
一系列的依赖:RDD1转换为RDD2,RDD2转换为RDD3,那么RDD3就依赖于RDD2,RDD2就依赖于RDD1。
即 Lineage(血统)。
4、Optionally, a Partitioner for key-value RDDs (分区器作用在 KV 格式的 RDD 上)
如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。
对于key-value的RDD可指定一个partitioner,告诉它如何分区;常用的有hash,range。
5、Optionally, a list of preferred locations to compute each split on (每个分片都有一系列的最佳计算位置)
要运行的计算/执行最好在哪(几)个机器上运行 。来实现数据本地性。
比如:hadoop默认有三个位置,或者spark cache到内存是可能通过StorageLevel设置了多个副本,所以一个partition可能返回多个最佳位置。
哪里体现RDD的弹性(容错)?
partition数量,大小没有限制,体现了RDD的弹性。
RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
哪里体现RDD的分布式?
RDD是由Partition组成,partition是分布在不同节点上的。
计算向数据移动?
RDD提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动,数据不移动”的理念。
代码流程
Config
集群配置,设置运行模式
SparkContext
集群上下文,通往集群入口
分布式文件系统(File system)
加载RDD。
transformations延迟执行
针对RDD的操作。
transformations是某一类算子(函数)。
Action触发执行Job
Action也是一类算子(函数)。
关闭Spark上下文对象SparkContext。
创建RDD的方式
textFile
从本地或hdfs读取数据,返回RDD,懒执行
parallelize
从集合返回RDD
makeRDD
同上
创建KV格式RDD的方式
parallelize
makeRDD
算子(例:map)返回二元组
主要算子
transformations(懒执行) 与 action 算子 (触发Job)

控制算子:
RDD的持久化 :
每个action算子执行,会把它所依赖的RDD重新计算一遍,这时应该对会重复计算的RDD持久化一把,缓存起来,下次就需要重新计算了。
控制算子有三种,cache,persist,checkpoint:
以上算子都可以将RDD持久化,持久化的单位是partition。
cache和persist都是懒执行的。必须有一个action类算子触发执行。
checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
persist
persist 持久化单位为partition
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1
)object StorageLevel {
// 不缓存
val NONE = new StorageLevel(false, false, false, false)
// 仅仅使用磁盘存储RDD的数据(未经序列化)。
val DISK_ONLY = new StorageLevel(true, false, false, false)
// 2的意思是会将数据备份到集群中两个不同的节点,其余情况类似。
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
// 默认选项,RDD的(分区)数据直接以Java对象的形式存储于JVM的内存中,如果内存空间不足,某些分区的数据将不会被缓存
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
// RDD的数据(Java对象)序列化之后存储于JVM的内存中
// 能够有效节约内存空间,但读取数据时需要更多的CPU开销
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
// RDD的数据直接以Java对象的形式存储于JVM的内存中
// 如果内存空间不中,某些分区的数据会被存储至磁盘,使用的时候从磁盘读取。
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
// 与 MEMORY_AND_DISK 相同,除了会序列化
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
// RDD的数据序例化之后存储至Tachyon (基于内存的文件系统)
// 默认未与Spark整合,未整合设置会报错
val OFF_HEAP = new StorageLevel(false, false, true, false)使用
rdd.persist(StorageLevel.MEMORY_ONLY)清除缓存(一般不需要,Spark会自动处理)
rdd.unpersit()cache
简化版 persist ,持久化等级为 MEMORY_ONLY
1、cache和persist都是懒执行,需要action类算子触发执行
2、cache或者persist的返回值必须赋值给一个变量(不然没有意义,因为没有引用)
在接下来的job中直接使用这个变量那就是使用了内存中的数据了
3、cache和persist后面不能立即紧跟action类算子 (也没意义,因为action类算子返回值不是RDD)
问题:在一个job中对某一个 RDD进行频繁的重复操作,有必要进行持久化吗?
没有必要!!! 因为持久化的算子只有遇到action类算子 才会将RDD的数据写入到内存中
val rdd = sc.textFile(path)
val filterRDD = rdd.filter
val mapRDD = rdd.map
val unionRDD = filterRDD.union(mapRDD)
unionRDD.count
val cacheRDD = rdd.cache
使用
rdd.cache()checkpoint
persist 和 cache 只能将 rdd 持久化到内存或者磁盘上
而checkpoint可以将RDD存到更加安全的hdfs(也可以是磁盘路径),适用于计算复杂耗时的RDD.
1、当action的算子触发的 Job 执行完毕后,会从 finalRDD 往前回溯,遇到调用过的 checkpoint 的RDD后,就会做一个标记,等全部回溯完毕后,那么所有调用过checkpoint的RDD都会被做标记了
2、会启动一个新的 Job,这个 Job 会重新计算被 checkpoint 标记过的RDD的数据,并且将这些RDD的计算结果写入指定的hdfs路径之下。
3、在成功写入hdfs后,会切断这个RDD的依赖关系,强制改变依赖为这个hdfs上的checkpointRDD
优化:在调用checkpoint之前最好先 cache 一下,这样在回溯计算时就不用重新计算了
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("checkpoint");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setCheckpointDir("./checkpoint");
JavaRDD<Integer> parallelizeRDD = sc.parallelize(Arrays.asList(1,2,3));
parallelizeRDD .checkpoint();
parallelizeRDD .count();
sc.stop();
术语解释
Master(standalone):资源管理的主节点(进程)
Cluster Manager:在集群上获取资源的外部服务(例如standalone,Mesos,Yarn )
Worker Node(standalone):资源管理的从节点(进程) 或者说管理本机资源的进程
Application:基于Spark的⽤用户程序,包含了driver程序和运行在集群上的executor程序
Driver Program:用来连接工作进程(Worker)的程序
Executor:是在一个worker进程所管理的节点上为某Application启动的⼀一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应⽤用都有各自独⽴立的executors
Task:被送到某个executor上的工作单元
Job:包含很多任务(Task)的并行计算,可以看做和action对应
Stage:⼀个Job会被拆分很多组任务,每组任务被称为Stage(就像Mapreduce分map task和reduce task一样)
Spark集群的搭建
1、下载安装包,解压
2、修改conf配置文件的名称 spark-env.sh slaves
3、修改slaves配置文件
添加从节点ip或者hostname
4、修改spark-env.sh配置文件
export SPARK_MASTER_IP : 绑定mastser ip
SPARK_MASTER_PORT : 端口
SPARK_WORKER_MEMORY:每一个Worker进程可支配的最大内存量
SPARK_WORKER_CORES : 每个Worker使用的Core数
SPARK_WORKER_INSTANCE:在每一个物理机或者虚拟机启动多少个Worker进程
5、同步到其他的节点上
6、启动命令在安装包的sbin下 start-all.sh
7、WEB UI 端口 8080,可以修改,两种方式
在spark-env.sh添加SPARK_MASTER_WEBUI_PORT
修改sbin下的start-master.sh脚本,将8080修改
8、搭建客户端(建议)
将spark安装包原封不动的拷贝到一个新的节点上,然后,在新的节点上提交任务即可。
9、测试 PI案例:
提交Application的命令在 ./bin/spark-submit
./spark-submit --master spark://hadoop1:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-e xamples-1.6.0-hadoop2.6.0.jar 100Spark-Submit提交参数:
Options:
--help
帮助
--master
Master_url , 可以是 spark,mesos,yarn
spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local
--deploy-mode
部署模式,客户端还是集群模式, Driver程序运行的地方,client或者cluster,默认是client。
--class
主类名称,含包名
--driver-class-path
driver所依赖的包,多个包之间用 冒号(:) 分割
--jars
driver和executor都需要的包,多个包之间用 逗号(,) 分割
--files
用 逗号 隔开的文件列表,会放置在每个executor工作目录中
--conf
spark的配置属性