HBase Shell && SQL
hbase shell常用的操作命令有 create,describe,disable,drop,list,scan,put,get,delete,deleteall,cou nt,status等
分类:
| general | tatus, version |
| ddl | alter, create, describe, disable,drop, enable, exists, is_disabled, is_enabled, list |
| dml | count, delete, deleteall, get,get_counter, incr, put, scan, truncate |
| tools | assign, balance_switch, balancer,close_region, compact, flush, major_compact, move, split, unassign, zk_dump |
| replication | add_peer, disable_peer,enable_peer, remove_peer, start_replication, stop_replication |
HBase中结束不能带 ’ ; ‘ 号
一、DDL操作
1、建立一个表create
create 'member','member_id', 'info' 2、查看当前HBase中具有哪些表list
list3、查看表的构造describe
describe 'member' 4、增加一个列族
修改表结构需要先disable,在enable
disable '表名'
alter '表名', {NAME => 'f1', VERSIONS => 5}
disable '表名'5、删除一个列族
disable 'member'
alter 'member',{name='member_id',METHOD=>'delete'}
enable 'member'6、删除表disable drop
disable 'member'
drop 'member'二、DML操作
(1)、增
put
插入或更新
语法:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
put 'member','zhangsan','info:age' ,'99'(2)、查
get
用法比较单一
1)查询数据
2)查询某行记录
语法:get <table>,<rowkey>,[<family:column>,....]
1、获取一行
get ‘member’,'rowid'2、获取一个id,一个列族的所有列此行数据
get 'member','zhangsan','info' 3、通过时间戳获得几个版本数据
get 'member','zhangsan',{COLUMN=>'info:age',TIMESTAMP=>1321586238965}scan
语法:scan <table>, {COLUMNS => [ <family:column>,.... ], LIMIT => num}
另外,还可以添加STARTROW、TIMERANGE和FITLER等高级功能
1、扫描全表
scan 'member'2、获取一列族
scan 'tbl',{COLUMNS=>'cf1'}3、获取一列
scan 'tbl',{COLUMNS=>'cf1:phonenum'}4、获取几列族
scan 'tbl',{COLUMNS=>['cf1','cf2']}5、扫描表t1的前5条数据
scan 'member',{LIMIT=>5}count
查询表中的数据行数
语法:count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
例如,查询表member中的行数,每100条显示一次,缓存区为500
count 'member', {INTERVAL => 100, CACHE => 500}filter
值相等过滤
scan 'member', FILTER=>"ValueFilter(=,'info:sxt')"谁的值包含88
scan member', FILTER=>"ValueFilter(=,'substring:88')"
列过滤
scan 'member', FILTER=>"ColumnPrefixFilter('info') AND ValueFilter(=,'substring:88')"前缀过滤
scan 'member', FILTER => "PrefixFilter ('user1')"rowkey范围过滤
scan 'member', {STARTROW=>'user1', STOPROW=>'user2'}rowkey相等过滤
查询rowkey里面包含ts3的
import org.apache.hadoop.hbase.filter.CompareFilter
import org.apache.hadoop.hbase.filter.SubstringComparator
import org.apache.hadoop.hbase.filter.RowFilter
scan 'member', {FILTER => RowFilter.new(CompareFilter::CompareOp.valueOf('EQUAL'), SubstringComparator.new('ts3'))}(3)、删
delete
删除数据
a )删除某行某个列值
语法:delete <table>, <rowkey>, <family:column> , <timestamp>,必须指定列名
例如:删除表member,rowkey001中的f1:info的数据
delete 'member','rowkey001','f1:info'注:将删除改行f1:col1列所有版本的数据
b )删除整个行
语法:deleteall <table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,删除整行数据
例如:删除表member,rowk001的数据
deleteall 'member','rowkey001'c)删除表中的所有数据
语法: truncate <table>
其运行具体过程是:disable table -> drop table -> create table
truncate 'member'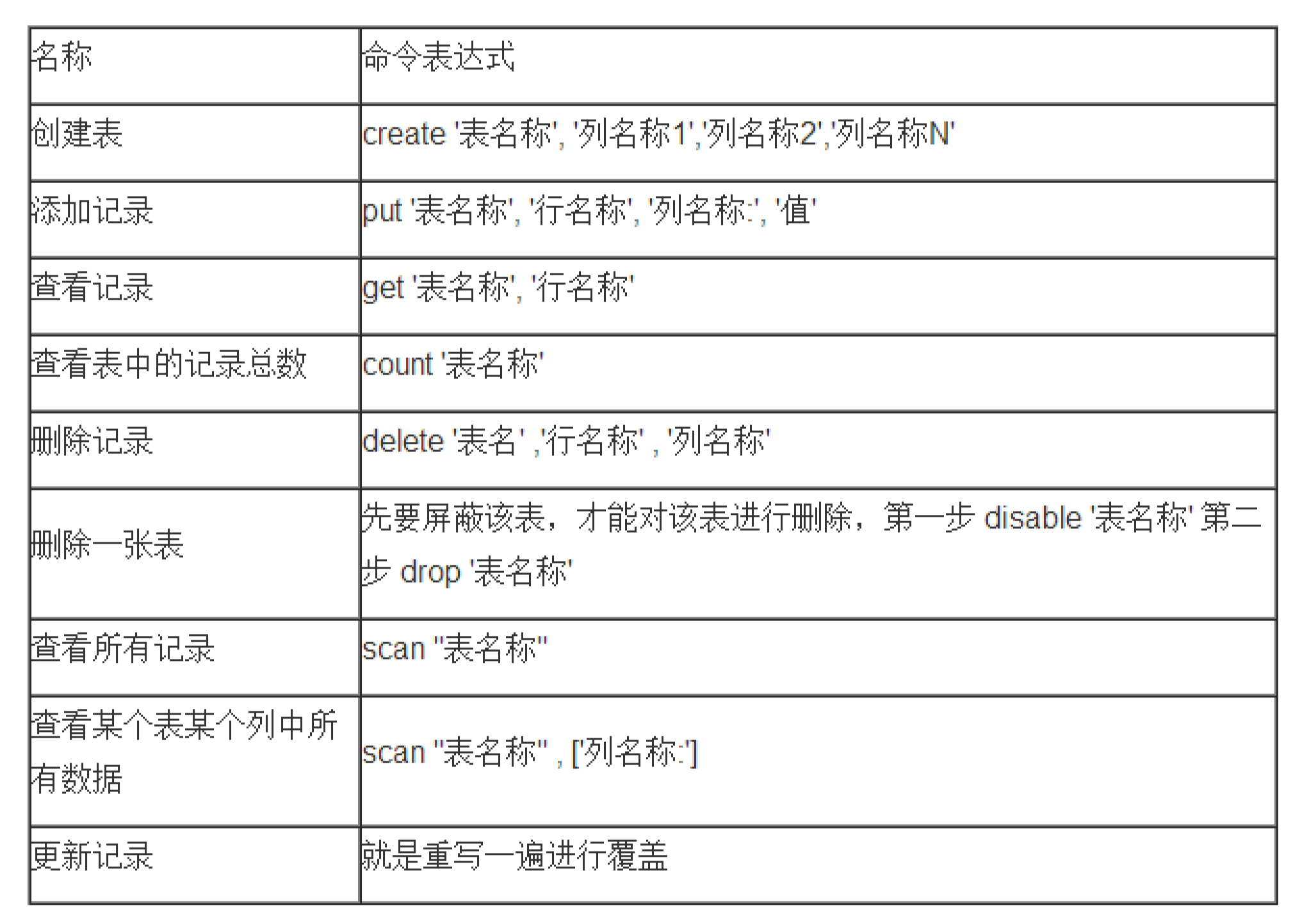
java代码
CONF
HBaseAdmin hBaseAdmin;
HTable hTable;
// 表名
String TN = "tbl";
@Before
public void setup() throws Exception {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "node01,node02,node03");
hBaseAdmin = new HBaseAdmin(conf);
hTable = new HTable(conf, TN);
}创建表
public void createTable() throws Exception {
HTableDescriptor desc = new HTableDescriptor(TableName.valueOf(TN));
HColumnDescriptor cf1 = new HColumnDescriptor("cf1");
cf1.setInMemory(true);
cf1.setMaxVersions(1);
desc.addFamily(cf1);
if(hBaseAdmin.tableExists(TN)) {
hBaseAdmin.disableTable(TN);
hBaseAdmin.deleteTable(TN);
}
hBaseAdmin.createTable(desc);
} 删除表
public void dropTable() throws Exception {
hBaseAdmin.disableTable(hTable.getName());
hBaseAdmin.deleteTable(hTable.getName());
}删除表数据
public void deleteFromDB() throws Exception {
Delete delete = new Delete("18681581187_20161028022110".getBytes());
hTable.delete(delete);
}插入数据
public void insertDB() throws Exception {
String pNum = getPhone("186");
// rowkey: 手机号+时间
Put put = new Put((pNum + "_" + getDate("2016")).getBytes());
put.add("cf1".getBytes(), "phonenum".getBytes(), pNum.getBytes());
// tnum 对方手机号
put.add("cf1".getBytes(), "tnum".getBytes(), getPhone("177").getBytes());
// type 主叫或者被叫 1 0
put.add("cf1".getBytes(), "type".getBytes(), "1".getBytes());
hTable.put(put);
}插入几行
public void insertDBs() throws Exception {
List<Put> puts = new ArrayList<Put>();
// rowkey 手机号+MAX-timestamp
for (int i = 0; i < 10; i++) {
// 手机号
String pNum = getPhone("186");
for (int j = 0; j < 100; j++) {
String dateStr = getDate("2016");
try {
String rowkey = pNum + "_"
+ (Long.MAX_VALUE - sdf.parse(dateStr).getTime());
Put put = new Put(rowkey.getBytes());
put.add("cf1".getBytes(), "phonenum".getBytes(),
pNum.getBytes());
// tnum 对方手机号
put.add("cf1".getBytes(), "tnum".getBytes(),
getPhone("177").getBytes());
// type 主叫或者被叫 1 0
put.add("cf1".getBytes(), "type".getBytes(),
(r.nextInt(2) + "").getBytes());
// 时间
put.add("cf1".getBytes(), "date".getBytes(),
dateStr.getBytes());
puts.add(put);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
hTable.put(puts);
}读取一行
public void getDB() throws Exception {
Get get = new Get("18681581187_20161028022110".getBytes());
get.addColumn("cf1".getBytes(), "phonenum".getBytes());
Result rs = hTable.get(get);
Cell cell = rs.getColumnLatestCell("cf1".getBytes(),"phonenum".getBytes());
System.out.println(new String(CellUtil.cloneValue(cell)));
}读取几行
public void ScanDB() throws Exception {
Scan scan = new Scan();
// 范围查询的起始 rowkey
String startRowkey = "18698781735" + "_" + (Long.MAX_VALUE - sdf.parse("20160201000000").getTime());
// 范围查询的结束 rowkey
String stopRowkey = "18698781735" + "_" + (Long.MAX_VALUE - sdf.parse("20160101000000").getTime());
scan.setStartRow(startRowkey.getBytes());
scan.setStopRow(stopRowkey.getBytes());
ResultScanner rss = hTable.getScanner(scan);
for (Result rs : rss) {
System.out.print(new String(CellUtil.cloneValue(rs.getColumnLatestCell("cf1".getBytes(), "phonenum".getBytes()))));
System.out.print("-" + new String(CellUtil.cloneValue(rs.getColumnLatestCell("cf1".getBytes(), "tnum".getBytes()))));
System.out.print("-" + new String(CellUtil.cloneValue(rs.getColumnLatestCell("cf1".getBytes(), "type".getBytes()))));
System.out.println("-" + new String(CellUtil.cloneValue(rs.getColumnLatestCell("cf1".getBytes(), "date".getBytes()))));
}
}过滤器
public void scanDBs() throws Exception {
Scan scan = new Scan();
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ALL);
// 前缀过滤
PrefixFilter prefixFilter = new PrefixFilter("18698781735".getBytes());
list.addFilter(prefixFilter);
SingleColumnValueFilter columnValueFilter = new SingleColumnValueFilter(
"cf1".getBytes(),
"type".getBytes(),
CompareOp.EQUAL,
Bytes.toBytes("1")
);
list.addFilter(columnValueFilter);
scan.setFilter(list);
ResultScanner rss = hTable.getScanner(scan);
for (Result rs : rss) {
System.out.print(new String(CellUtil.cloneValue(rs.getColumnLatestCell("cf1".getBytes(), "phonenum".getBytes()))));
System.out.print("-" + new String(CellUtil.cloneValue(rs.getColumnLatestCell("cf1".getBytes(), "tnum".getBytes()))));
System.out.print("-" + new String(CellUtil.cloneValue(rs.getColumnLatestCell("cf1".getBytes(), "type".getBytes()))));
System.out.println("-" + new String(CellUtil.cloneValue(rs.getColumnLatestCell("cf1".getBytes(), "date".getBytes()))));
}
}HBase表设计
1、人员-角色
人员有多个角色 角色优先级
角色有多个人员
人员 删除添加角色
角色 可以添加删除人员
人员 角色 删除添加
************************************************************************************
#人员表staff
| rowkey | cf1(人员的基本信息) | cf2(角色列表) |
| sid | cf1:sname=..;cf1:age=.. | cf2:rid=x(优先级) |
例 001 cf1:name=zhangsan cf2:101=1;cf2:102=2
#角色表
| rowkey | cf1(角色的基本信息) | cf2(人员列表) |
| rid | cf1:name=CTO;cf1:... | cf2:sid=sname |
例:
101 cf1:name=CTO cf2:001=zhangsan
102 cf1:name=CEO cf2:001=zhangsan
2、组织架构 部门-子部门
查询 顶级部门
查询 每个部门的所有子部门
部门 添加、删除子部门
部门 添加、删除
************************************************************************************
部门表:
rowkey规则 部门的id:0_代表父目录,1_代表子目录
| rowkey | cf1(部门基本信息) | cf2(子部门列表) |
| 0_000 | cf1:name=BOSS;cf1:parentNo='';.. | cf2:id=nam |
例:
0_000 cf1:name=BOSS;cf1:parentNo='';.. cf2:1_001=Manager;1_002:CEO
1_001 cf1:name=Manager;cf1:parentNo=0_000
1_002 cf1:name=CEO;cf1:parentNo=0_000
3、微博
看微博 首页
所有关注的用户发布的微博 降序排列
添加关注、删除关注好友 查看粉丝列表
查看每个微博用户所发布的微博 降序排列
发布微博
************************************************************************************
1、关注粉丝表
| rowkey | cf1(关注列表) | cf2(粉丝列表) |
| pid | cf1:pid='';cf1:pid='';.. | cf2:pid='';cf2:pid='';.. |
例:
小明
001 cf1:002=李雷 cf2:002=李雷
李雷
002 cf1:003=韩梅梅;cf1:001=小明 cf2:001=小明
韩梅梅
003 cf2:002=李雷
2、微博
| rowkey | cf1(微博内容) |
| pid_(MAX-time) | cf1:context='xxx' |
例:
101_123456 cf1:context=helloword
001_234567 cf1:context=byebyeword
003_987664 cf1:context=hiword
3、收取微博表
| rowkey | cf1 |
| pid | cf1:get=微博id version=1000 |
例:
002 cf1:get=003_987664
002 cf1:get=003_987664
get=001_234567
************************************************************************************