什么是pagerank
– PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎 索引中的其他网页而言的重要程度。
– 是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的
– PageRank实现了将链接价值概念作为排名因素。
• 计算环境
– Hadoop-2.5.2
– 四台主机
– 两台NN的HA
– 两台RM的HA
– 离线计算框架MapReduce
算法原理(1)
– 入链 ====投票
• PageRank让链接来“投票“,到一个页面的超链接相当于对该页投一票 。
– 入链数量
• 如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面 越重要。
– 入链质量
• 指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更 多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
算法原理(2)
– 初始值
• 每个页面设置相同的PR值
• Google的pagerank算法给每个页面的PR初始值为1。
– 迭代递归计算(收敛)
• Google不断的重复计算每个页面的PageRank。那么经过不断的重复计算 ,这些页面的PR值会趋向于稳定,也就是收敛的状态。
• 在具体企业应用中怎么样确定收敛标准?
– 1、每个页面的PR值和上一次计算的PR相等
– 2、设定一个差值指标(0.0001)。当所有页面和上一次计算的PR差值平均小 于该标准时,则收敛。
– 3、设定一个百分比(99%),当99%的页面和上一次计算的PR相等

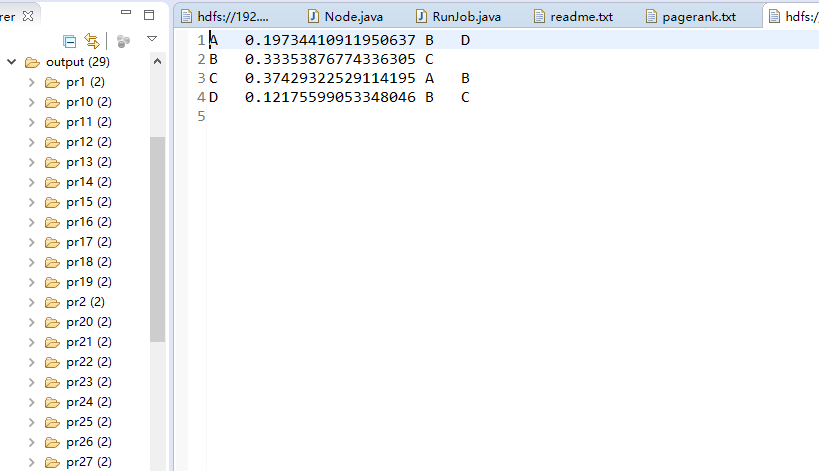
如图第一轮
ABCD的初始权重PR=1
A分别给BD各投一票,A的PR=1,所以的BD分别得到的pr为1/2(PR除总投票数),照此计算,第一轮投票后的PR为
投票前 投票后
A 1 3/2
B 1 5/2
C 1 5/2
D 1 3/2
第一轮结束后各点的PR开始不同,所以在第二轮投票(即重新计算一次)每点的票的重量会不同
投票前 投票后
A 3/2 11/4
B 5/2 21/4
C 5/2 23/4
D 3/2 9/4
第二轮结束后C的PR最高,虽然B的得票最多的。
算法原理(3)
– 修正PageRank计算公式
• 由于存在一些出链为0,也就是那些不链接任何其他网页的网, 也称为孤 立网页,使得很多网页能被访问到。因此需要对 PageRank公式进行修正 ,即在简单公式的基础上增加了阻尼系数(damping factor)q, q一般 取值q=0.85。
– 完整PageRank计算公式
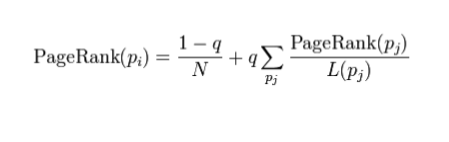
pagerank公式中
p1,p2,p3...pn代表n个不同的网页,M(i)是链接到pi的所有网页的集合,
L(j)是pj网页上的外链数。d (0 < d ≤ 1)是阻尼因子,表示用户继续点击链接而不是随机打开其他网页的概率。
实现pagerank
测试数据
A B D
B C
C A B
D B C
第一行代表A给BD投了票
1、定义收敛标准
每次算出新的pr-oldpr=差值 ,所有页面的差值累加 ,除以pagecount,得到avg差值 ,如果。小于0.01
这重复计算以下步骤
2、计算总页面数,并且算出每个页面的初始pr值=1/pagecount
3、A 0.25 B D ----- A 0.35 B D--- A 0.29 B D----
代码
/**
* 将字符串 转换为Node对象 字符串 :0.5 B D
* @author root
*
*/
public class Node {
// 字符串中 第一个元素 初始PR值 为 1
private double pageRank = 1.0;
// 字符串中 后面的节点列表 数组
private String[] adjacentNodeNames;
// PR值 与 数组的分隔符 \t
public static final char fieldSeparator = '\t';
public double getPageRank() {
return pageRank;
}
public Node setPageRank(double pageRank) {
this.pageRank = pageRank;
return this;
}
public String[] getAdjacentNodeNames() {
return adjacentNodeNames;
}
public Node setAdjacentNodeNames(String[] adjacentNodeNames) {
this.adjacentNodeNames = adjacentNodeNames;
return this;
}
public boolean containsAdjacentNodes() {
return adjacentNodeNames != null && adjacentNodeNames.length > 0;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(pageRank);
if (getAdjacentNodeNames() != null) {
sb.append(fieldSeparator).append(
StringUtils.join(getAdjacentNodeNames(), fieldSeparator));
}
return sb.toString();
}
// value =1.0 B D
public static Node fromMR(String value) throws IOException {
String[] parts = StringUtils.splitPreserveAllTokens(value, fieldSeparator);
if (parts.length < 1) {
throw new IOException("Expected 1 or more parts but received " + parts.length);
}
// 1.0 A B D
Node node = new Node().setPageRank(Double.valueOf(parts[0]));
if (parts.length > 1) {
node.setAdjacentNodeNames(Arrays.copyOfRange(parts, 1, parts.length));
}
return node;
}
}
public class RunJob {
public static enum Mycounter {
//枚举
my
}
public static void main(String[] args) {
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://node01:8020");
config.set("yarn.resourcemanager.hostname", "node03");
// config.set("mapred.jar", "D://MR/jar/pagerank.jar");
// 收敛值
double d = 0.001;
int i = 0;
while (true) {
i++;
try {
// 记录计算的次数
config.setInt("runCount", i);
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJarByClass(RunJob.class);
job.setJobName("pr" + i);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
Path inputPath = new Path("/MR/pagerank/input/pagerank.txt");
if (i > 1) {
inputPath = new Path("/MR/pagerank/output/pr" + (i - 1));
}
FileInputFormat.addInputPath(job, inputPath);
Path outpath = new Path("/MR/pagerank/output/pr" + i);
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
if (f) {
System.out.println("success.");
// 获取 计数器 中的差值
long sum = job.getCounters().findCounter(Mycounter.my).getValue();
System.out.println("SUM: " + sum);
double avgd = sum / 4000.0;
if (avgd < d) {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
static class PageRankMapper extends Mapper<Text, Text, Text, Text> {
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
int runCount = context.getConfiguration().getInt("runCount", 1);
// A B D
String page = key.toString();
Node node = null;
if (runCount == 1) { //第一次计算 初始化PR值为1.0
node = Node.fromMR("1.0" + "\t" + value.toString());
} else {
node = Node.fromMR(value.toString());
}
// A:1.0 B D
// 将计算前的数据输出 reduce计算做差值
context.write(new Text(page), new Text(node.toString()));
if (node.containsAdjacentNodes()) {
double outValue = node.getPageRank() / node.getAdjacentNodeNames().length;
for (int i = 0; i < node.getAdjacentNodeNames().length; i++) {
String outPage = node.getAdjacentNodeNames()[i];
// B:0.5
// D:0.5
context.write(new Text(outPage), new Text(outValue + ""));
}
}
}
}
static class PageRankReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> iterable, Context context)
throws IOException, InterruptedException {
double sum = 0.0;
Node sourceNode = null;
for (Text i : iterable) {
Node node = Node.fromMR(i.toString());
//A:1.0 B D
if (node.containsAdjacentNodes()) {
// 计算前的数据 // A:1.0 B D
sourceNode = node;
} else {
// B:0.5 // D:0.5
sum = sum + node.getPageRank();
}
}
// 计算新的PR值 4为页面总数
double newPR = (0.15 / 4.0) + (0.85 * sum);
System.out.println("*********** new pageRank value is " + newPR);
// 把新的pr值和计算之前的pr比较
double d = newPR - sourceNode.getPageRank();
int j = (int) (d * 1000.0);
j = Math.abs(j);
System.out.println(j + "___________");
// 累加
context.getCounter(Mycounter.my).increment(j);
sourceNode.setPageRank(newPR);
context.write(key, new Text(sourceNode.toString()));
}
}
}
运行29次之后达到收敛标准