批处理与流式处理区别


应用场景例子

Storm介绍
Storm是个 实时 的、分布式以及具备高容错的计算系统
Storm进程常驻内存
Storm数据不经过磁盘,在内存中处理
Twitter开源的分布式实时大数据处理框架,最早开源于github
2013年,Storm进入Apache社区进行孵化
2014年9月,晋级成为了Apache顶级项目
国内外各大网站使用,例如雅虎、阿里、百度
架构
角色
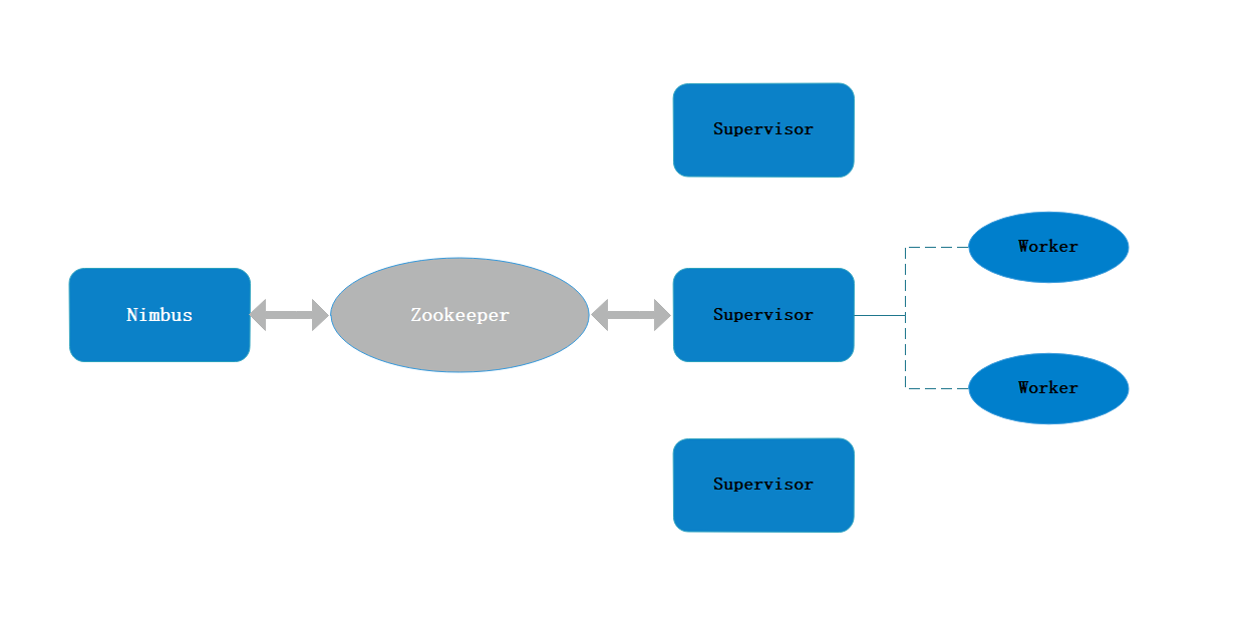
Nimbus
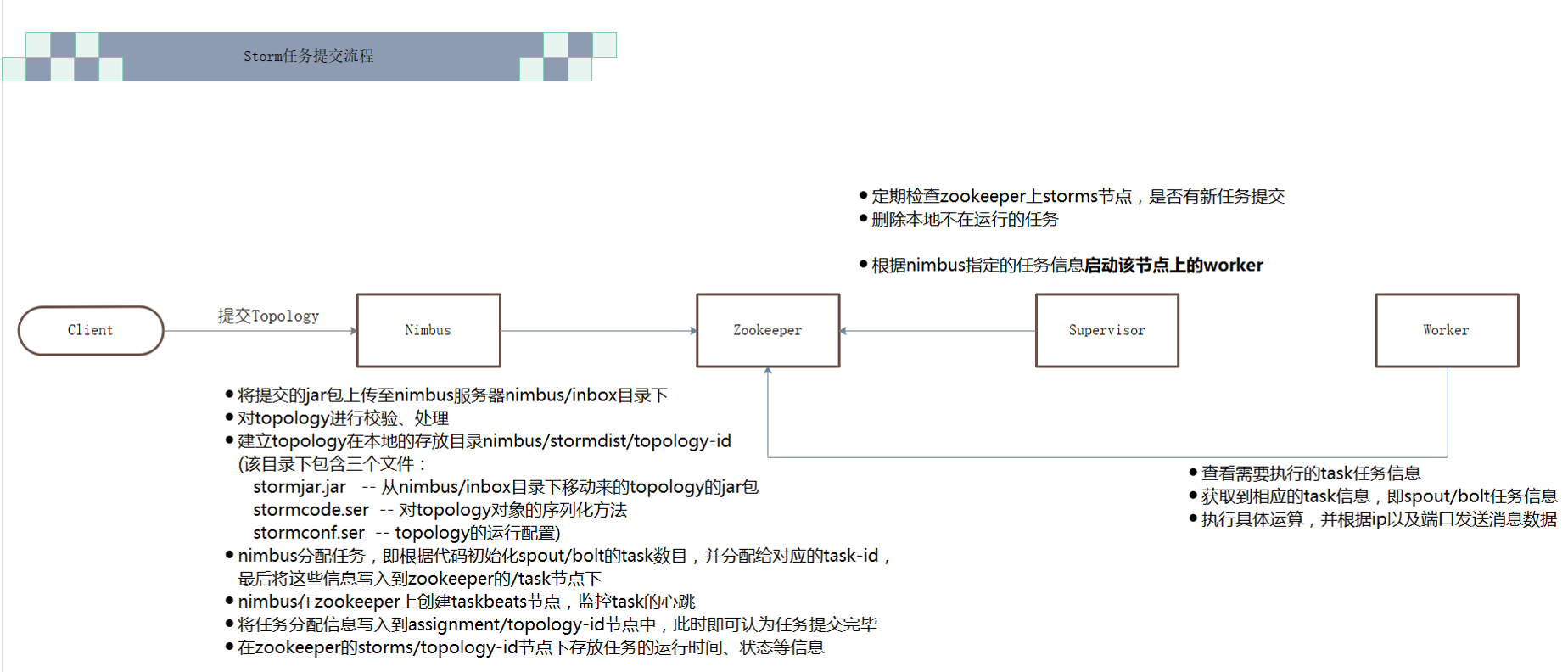
资源调度
任务分配
接收jar包
Supervisor
接收nimbus分配的任务
启动、停止自己管理的worker进程(当前supervisor上worker数量由配置文件设定)
Worker
运行具体处理运算组件的进程(每个Worker对应执行一个Topology的子集)
worker任务类型,即spout任务、bolt任务两种
启动executor
(executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务)
Zookeeper
监控节点心跳,与task执行情况
编程模型
DAG (Topology) -- 有向无环图
Spout -- 数据读取传递源
Bolt -- 数据处理中间节点
详细介绍:Storm 计算模型
数据传输
ZMQ
ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
Netty
Netty是基于NIO的网络框架,更加高效。
(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
Storm架构设计与Yarn架构对比

优点
高可靠性
异常处理
消息可靠性保障机制
可维护性
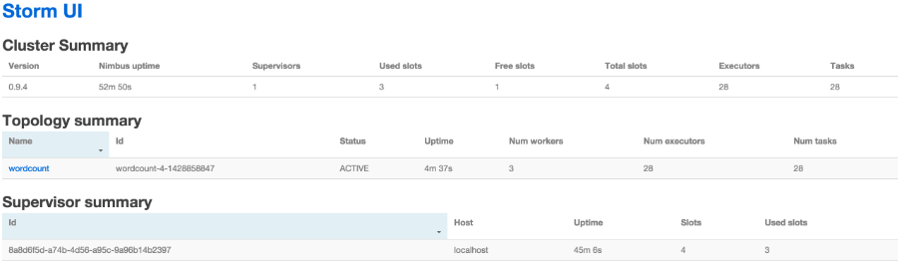
StormUI 图形化监控接口
流式处理
1、异步
客户端提交数据进行结算,并不会等待数据计算结果
场景
逐条处理
例:ETL
统计分析
例:计算PV、UV、访问热点 以及 某些数据的聚合、加和、平均等
客户端提交数据之后,计算完成结果存储到Redis、HBase、MySQL或者其他MQ当中,
客户端并不关心最终结果是多少。

2、同步
客户端提交数据请求之后,立刻取得计算结果并返回给客户端
场景
Drpc
实时请求处理
例:图片特征提取

Storm 对比 MapReduce
Storm
进程、线程常驻内存运行,数据不进入磁盘,数据通过网络传递。
MapReduce
为TB、PB级别数据设计的批处理计算框架。
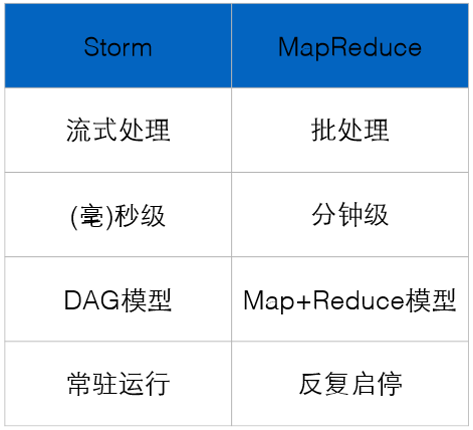
Storm 对比 SparkStreaming
Storm : 纯流式处理
专门为流式处理设计
数据传输模式更为简单,很多地方也更为高效
并不是不能做批处理,它也可以来做微批处理,来提高吞吐
Spark Streaming : 微批处理
将RDD做的很小来用小的批处理来接近流式处理
基于内存和DAG可以把处理任务做的很快
Storm是纯实时的,SparkSteaming是微批处理,微批处理效率更高吞吐量更大
Storm对于事务支持要比SparkStreaming要好
对于流式处理框架,事务就是数据恰好处理一次,
对于对数据安全要求的如银行,选用storm
Storm支持动态的资源扩展,SparkSteaming不支持
即动态对节点性能调整,高峰时加强,低峰时降低
SparkStreaming中可以使用sql语句来处理数据,Storm无法实现
Storm适合简单的汇总型计算,SparkStreaming适合复杂的数据处理
Storm 本地目录树

Storm Zookeeper目录树

Storm部署
一、环境要求
JDK 1.6+
java -version
Python 2.6.6+
python -V
ZooKeeper3.4.5+
storm 0.9.4+
二、单机模式
上传解压
tar xf apache-storm-0.9.4.tar.gz
cd apache-storm-0.9.4
mkdir logs
./bin/storm --help 下面分别启动ZooKeeper、Nimbus、UI、supervisor、logviewer
./bin/storm dev-zookeeper >> ./logs/zk.out 2>&1 &
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
./bin/storm ui >> ./logs/ui.out 2>&1 &
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
./bin/storm logviewer >> ./logs/logviewer.out 2>&1 & 需要等一会儿
jps 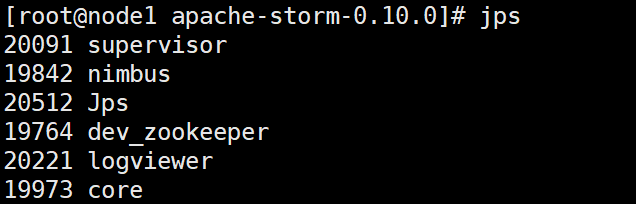
web UI
提交任务到Storm集群当中运行:
./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology wordcount
./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology test三、完全分布式安装部署
各节点分配:
Nimbus Supervisor Zookeeper
node1 1 1
node2 1 1
node3 1 1
node1作为nimbus
vim conf/storm.yamlstorm.zookeeper.servers:
- "node1"
- "node2"
- "node3"
storm.local.dir: "/tmp/storm"
nimbus.host: "node1"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703在storm目录中创建logs目录
mkdir logs 集群当中所有服务器,同步所有配置!
启动ZooKeeper集群
node1上启动Nimbus
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 & # 查看日志 tail -f logs/nimbus.log ./bin/storm ui >> ./logs/ui.out 2>&1 & # 查看日志 tail -f logs/ui.log
节点node2和node3启动supervisor,按照配置,每启动一个supervisor就有了4个slots
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
# 查看日志
tail -f logs/supervisor.log
#(当然node1也可以启动supervisor) web界面

提交任务到Storm集群当中运行:
./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology wordcount
./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology test 环境变量可以配置也可以不配置
export STORM_HOME=/opt/sxt/storm
export PATH=$PATH:$STORM_HOME/bin观察关闭一个supervisor后,nimbus的重新调度,再次启动一个新的supervisor后,观察,并rebalance