单机/单点
瓶颈处理:
多个节点负载:面向数据:一变多(一致性)
镜像:数据容量不变
切片:横向扩展
单点故障
集群分类
主从复制 Replication:镜像:增删改(主<退化到单节点>)查询负载到从节点
高可用 Sentinel
分布式 twemproxy:切片
集群 Cluster
一 、主从复制 Replication
一个Redis服务可以有多个该服务的复制品,这个Redis服务称为Master,其他复制品称为Slaves
只要网络连接正常,Master会一直将自己的数据更新同步给Slaves,保持主从同步
只有Master可以执行写命令,Slaves只能执行读命令,客户端连接Slaves执行读请求,来降低Master的读压力


1. 主从复制创建
三种
(1)、配置当前服务称为某Redis服务的Slave
# redis-server --slaveof <master-ip> <master-port>
redis-server --port 6380 --slaveof 127.0.0.1 6379(2)、SLAVEOF host port命令,将当前服务器状态从Master修改为别的服务器的Slave
# 将服务器转换为Slave
redis > SLAVEOF 192.168.1.1 6379
# 将服务器重新恢复到Master --不会丢弃已同步数据
redis > SLAVEOF NO ONE (2)、启动时,服务器读取配置文件,并自动成为指定服务器的从服务器
#slaveof <masterip> <masterport>
slaveof 127.0.0.1 63792. 主从复制问题
一个Master可以有多个Slaves
Slave下线,只是读请求的处理性能下降
Master下线,写请求无法执行
其中一台Slave使用SLAVEOF no one命令成为Master,其它Slaves执行SLAVEOF命令指向这个新的Master,从它这里同步数据
以上过程是手动的,能够实现自动,这就需要Sentinel哨兵,实现故障转移Failover操作
二、高可用 Sentinel 哨兵
官方提供的高可用方案,可以用它管理多个Redis服务实例
Redis Sentinel是一个分布式系统,可以在一个架构中运行多个Sentinel进程
监控 Monitoring
Sentinel会不断检查Master和Slaves是否正常
每一个Sentinel可以监控任意多个Master和该Master下的Slaves
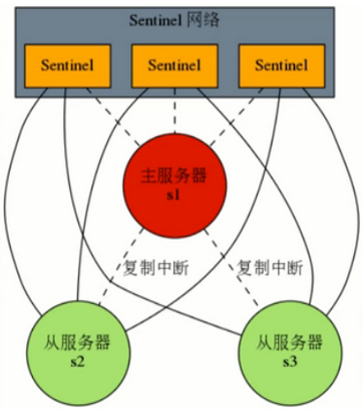
Sentinel网络
监控同一个Master的Sentinel会自动连接,组成一个分布式的Sentinel网络,互相通信并交换彼此关于被监视服务器的信息
服务器下线
当一个sentinel认为被监视的服务器已经下线时,它会向网络中的其他Sentinel进行确认,判断该服务器是否真的已经下线。
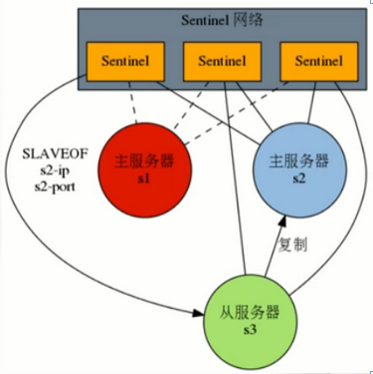
如果下线的服务器为主服务器,那么sentinel网络将对下线主服务器进行自动故障转移,通过将下线主服务器的某个从服务器提升为新的主服务器,并让其从服务器转为复制新的主服务器,以此来让系统重新回到上线的状态
服务器s1宕机 ——> 服务器s2升为主 ——> s1重新连接,为从

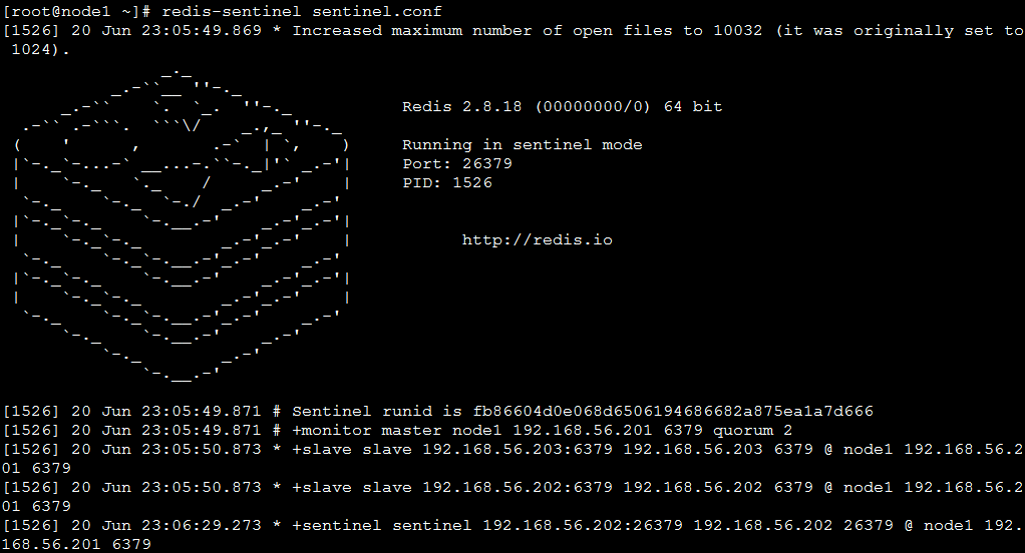
启动 Sentinel
将src目录下产生redis-sentinel程序文件复制到$REDIS_HOME/bin
启动一个运行在Sentinel模式下的Redis服务实例
> redis-sentinel
> redis-server /path/to/sentinel.conf --sentinelSentinel 配置文件
· 至少包含一个监控配置选项,用于指定被监控Master的相关信息
Sentinel monitor<name><ip><port><quorum> quorum : sentinel id
例如:
sentinel monitor node04 127.0.0.1 6379 2
监视mymaster的主服务器,服务器ip和端口,将这个主服务器判断为下线失效至少需要2个Sentinel同意,如果多数Sentinel同意才会执行故障转移
· Sentinel会根据Master的配置自动发现Master的Slaves
· Sentinel默认端口号为26379
例如:
port 26379
Sentinel 总结
主从复制,解决了读请求的分担,从节点下线,会使得读请求能力有所下降
Master只有一个,写请求单点问题
Sentinel会在Master下线后自动执行Failover操作,提升一台Slave为Master,并让其他Slaves重新成为新Master的Slaves
主从复制+哨兵Sentinel只解决了读性能和高可用问题,但是 没有解决写性能问题
三、Redis Twemproxy
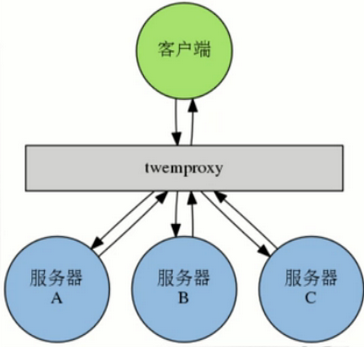
· Twitter开发的代理服务器,它兼容Redis和Memcached,允许用户将多个redis服务器添加到一个服务器池(pool)里面,并通过用户选择的散列函数和分布函数,将来自客户端的命令请求分发给服务器池中的各个服务器
· 通过使用twemproxy我们可以将数据库分片到多台redis服务器上面,并使用这些服务器来分担系统压力以及数据库容量:
在服务器硬件条件相同的情况下,对于一个包含N台redis服务器的池来说,池中每台平均1/N的客户端命令请求
· 向池里添加更多服务器可以线性的扩展系统处理命令请求的能力,以及系统能够保存的数据量
tar xf twemproxy-0.4.0.tar.gz
# 安装autoconf
# 由于CentOS 6.x autoconf版本太低,不用yum安装,手动安装
tar xf autoconf-2.69.tar.gz
cd autoconf-2.69
./configure --prefix=/usr
make && make install
#查看是否安装成功
autoconf -V
#下载automake
tar xf automake-1.15.tar.gz
./configure --prefix=/usr
make && make install
#下载libtool
tar xf libtool-2.4.5.tar.gz
./configure --prefix=/usr
make && make install
# 安装twemproxy
tar xf twemproxy-0.4.1.tar.gz
cd twemproxy-0.4.1
aclocal
autoconf
mkdir config
autoheader
libtoolize
automake -a
./configure
make && make installTwemproxy配置
cluster:
listen: 192.168.26.11:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 3
servers:
- 192.168.26.11:6379:1
- 192.168.26.12:6379:1
- 192.168.26.13:6379:1配置说明:
| cluster | 服务器池的名字,支持创建多个服务器池 |
| listen: 192.168.26.11:22121 | 这个服务器池的监听地址和端口号 |
| hash: fnv1a_64 | 键散列算法,用于将键映射为一个散列值 |
| distribution: ketama | 键分布算法,决定键被分布到哪个服务器 |
| redis: true | 代理redis命令请求,不给定时默认代理memcached请求 |
| auto_eject_hosts | |
| server_failure_limit | twemproxy连续3次向同一个服务器发送命令请求都遇到错误时,twemproxy就会将该服务器标记为下线,并交由池中其他在线服务器处理 |
| servers | 池中各个服务器的地址和端口号及权重 |
| server_retry_timeout | 当一个服务器被twemproxy判断为下线之后,在time毫秒之内,twemproxy不会再尝试向下线的服务器发送命令请求,但是在time毫秒之后,服务器会尝试重新向下线的服务器发送命令请求 如果命令请求能够正常执行,那么twemproxy就会撤销对该服务器的下线判断,并再次将键交给那个服务器来处理 但如果服务器还是不能正常处理命令请求,那么twemproxy就会继续将原本应该交给下线服务器的键转交给其他服务器来处理,并等待下一次重试的来临 |
启动
启动redis服务,3个节点手工启动
service redisd start 启动twemproxy
nutcracker -d -c /opt/sxt/twemproxy/conf/nutcracker.sxt.yml
连接
redis-cli -p 22121 -h 192.168.26.11总结
前端使用 Twemproxy 做代理,后端的 Redis 数据能基本上根据 key 来进行比较均衡的分布。
后端一台 Redis 挂掉后,Twemproxy 能够自动摘除。恢复后,Twemproxy 能够自动识别、恢复并重新加入到 Redis 组中重新使用。
Redis 挂掉后,后端数据是否丢失依据 Redis 本身的持久化策略配置,与 Twemproxy 基本无关。
如果要新增加一台 Redis,Twemproxy 需要重启才能生效;并且数据不会自动重新 Reblance,需要人工单独写脚本来实现。
如原来已经有 2 个节点 Redis,后续有增加 2 个 Redis,则数据分布计算与原来的 Redis 分布无关,现有数据如果需要分布均匀的话,需要人工单独处理。如果 Twemproxy 的后端节点数量发生变化,Twemproxy 相同算法的前提下,原来的数据必须 重新处理分布,否则会存在找不到key值的情况
不管 Twemproxy 后端有几台 Redis,前端的单个 Twemproxy 的性能最大也只能和单台 Redis 性能差不多
如同时部署多台 Twemproxy 配置一样,客户端分别连接 多台 Twemproxy 可以在一定条件下提高性能
整合方案
redis-mgr
整合了通过整合复制、Sentinel以及twemproxy等组件,提供了一站式的Redis服务器部署、监控、迁移功能
网址:https://github.com/changyibiao/redis-mgr
四、Redis 3.0 集群
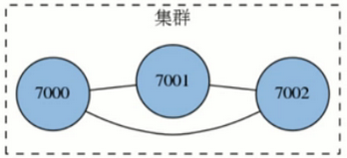
由多个Redis服务器组成的分布式网络服务集群
每一个Redis服务器称为节点Node,节点之间会互相通信。两两相连
Redis集群无中心节点
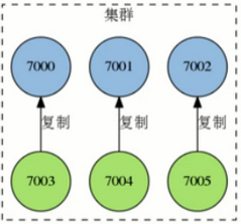
Redis集群节点复制
Redis集群的每个节点都有两种角色可选:主节点master node、从节点slave node。
其中主节点用于存储数据,而从节点则是某个主节点的复制品
当用户需要处理更多读请求的时候,添加从节点可以扩展系统的读性能。
因为Redis集群重用了单机Redis复制特性的代码,所以集群的复制行为和我们之前介绍的单机复制特性的行为是完全一样的
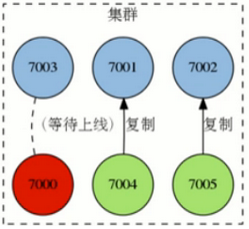
Redis集群故障转移
Redis集群的主节点内置了类似Redis Sentinel的节点故障检测和自动故障转移功能:
当集群中的某个主节点下线时,集群中的其他在线主节点会注意到这一点,并对已下线的主节点进行故障转移
集群进行故障转移的方法和Redis Sentinel进行故障转移的方法基本一样,不同的是,在集群里面,故障转移是由集群中其他在线的主节点负责进行的,所以集群不必另外使用Redis Sentinel。

Redis集群分片
集群将整个数据库分为 16384 个槽位slot,所有key都属于这些slot中的一个:
key的槽位计算公式为 slot_number= crc16(key) % 16384,其中crc16为16位的循环冗余校验和函数
集群中的每个主节点都可以处理0个至16383个槽,当16384个槽都有某个节点在负责处理时,集群进入上线状态,并开始处理客户端发送的数据命令请求
举例
三个主节点7000、7001、7002平均分片16384个slot槽位
节点7000指派的槽位为0到5460
节点7001指派的槽位为5461到10922
节点7002指派的槽位为10923到16383
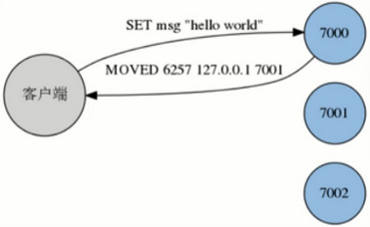
Redis集群Redirect转向
由于Redis集群无中心节点,请求 会发给任意主节点
主节点只会处理自己负责槽位的命令请求,其它槽位的命令请求,该主节点会返回客户端一个转向错误
客户端根据错误中 包含的地址和端口重新向正确的 负责的主节点发起命令请求
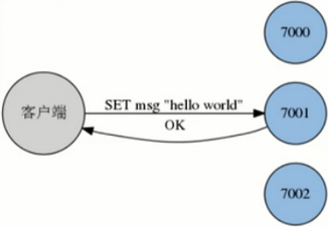
Redis集群搭建
# redis集群 3.x版本
# 物理节点1个
# 指定3个主节点端口为7000、7001、7002
# 对应的3个从节点端口为7003、7004、7005
mkdir cluster-test
cd cluster-test
mkdir 7000 7001 7002 7003 7004 7005
# 配置文件
# 开启集群模式
# cluster-enabled yes
# 指定不冲突的端口
# port <对应端口号>
# 在7000-7005目录中放入redis.conf
# redis.conf内容如下
cluster-enabled yes
port 700x
# 启动所有服务,要进入子目录启动服务
cd 700x
redis-server redis.conf
# ss -tanl | grep 700# 创建集群
yum install ruby rubygems -y
#redis模块安装
#在线安装
gem install redis
# 离线安装
# https://rubygems.org/gems/redis
gem install --local redis-3.3.0.gem
# 安装目录src中redis-trib.rb完成集群创建
# 在安装目录下的src中
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
以下是分配的信息展示
Using 3 masters:
127.0.0.1:7000
127.0.0.1:7001
127.0.0.1:7002
Adding replica 127.0.0.1:7003 to 127.0.0.1:7000
Adding replica 127.0.0.1:7004 to 127.0.0.1:7001
Adding replica 127.0.0.1:7005 to 127.0.0.1:7002
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: d4cbae0d69b87a3ca2f9912c8618c2e69b4d8fab 127.0.0.1:7000
slots:0-5460 (5461 slots) master
M: bc2e33db0c4f6a9065792ea63e0e9b01eda283d7 127.0.0.1:7001
slots:5461-10922 (5462 slots) master
M: 5c2217a47e03331752fdf89491e253fe411a21e1 127.0.0.1:7002
slots:10923-16383 (5461 slots) master
M: 3d4b31af7ae60e87eef964a0641d43a39665f8fc 127.0.0.1:7003
slots: (0 slots) master
replicates d4cbae0d69b87a3ca2f9912c8618c2e69b4d8fab
M: 710ba3c9b3bda175f55987eb69c1c1002d28de42 127.0.0.1:7004
slots: (0 slots) master
replicates bc2e33db0c4f6a9065792ea63e0e9b01eda283d7
M: 7e723cbd01ef5a4447539a5af7b4c5461bf013df 127.0.0.1:7005
slots: (0 slots) master
replicates 5c2217a47e03331752fdf89491e253fe411a21e1 自动分配了主从,自动分配了slots,所有槽都有节点处理,集群上线
客户端连接
redis-cli -p 7000 -c-c 使用集群模式,允许转向
Redis集群总结
Redis集群是一个由多个节点组成的分布式服务集群,它具有复制、高可用和分片特性
Redis的集群没有中心节点,并且带有复制和故障转移特性,这可用避免单个节点成为性能瓶颈,或者因为某个节点下线而导致整个集群下线
集群中的主节点负责处理槽(储存数据),而从节点则是主节点的复制品
Redis集群将整个数据库分为16384个槽,数据库中的每个键都属于16384个槽中的其中一个
集群中的每个主节点都可以负责0个至16384个槽,当16384个槽都有节点在负责时,集群进入上线状态,可以执行客户端发送的数据命令
主节点只会执行和自己负责的槽有关的命令,当节点接收到不属于自己处理的槽的命令时,它将会处理指定槽的节点的地址返回给客户端,而客户端会向正确的节点重新发送
五、方案的选择
如果需要完整地分片、复制和高可用特性,并且要避免使用代理带来的性能瓶颈和资源消耗,那么可以选择使用Redis集群;
如果只需要一部分特性(比如只需要分片,但不需要复制和高可用等),那么单独选用twemproxy、Redis的复制和Redis Sentinel中的一个或多个
| twemproxy | 集群 | |
| 运作模式 | 代理模式,代理本身可能成为性能瓶颈,随着负载的增加需要添加更多twemproxy来分担请求负载,但每个twemproxy本身也会消耗一定的资源 | 分布式,没有中心节点,但是因为每个节点都需要互相进行数据通信,所以在节点数量多时,集群用于进行通信所耗费的网络资源会比较多 |
| 分片 | 基本上是按照池中的服务器数量N来分片,每个服务器平均占整个数据库的1/N | 按照槽来进行分片,通过每个节点指派不同数量的槽,可以控制不同节点负责数据量和请求数量 |
| 复制和高可 用 | 需要配合Redis的复制特性以及Redis Sentinel才能实现复制和高可用 | 集群的节点内置了复制和高可用特性 |