Hive是构建在hadoop之上的数据仓库。不是用来增删改查的那种数据库,Hive是数据仓库
1)数据计算是MapReduce
2)数据存储是HDFS
Hive 是基于 Hadoop 构建的一套数据仓库分析系统,它提供了丰富的 SQL 查询方式来分析存储在 Hadoop 分布式文件系统中的数据, 可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行,通过自己的 SQL 去 查询分析需要的内容,这套 SQL 简称 Hive SQL,使不熟悉 MapReduce 的用户很方便地利用 SQL 语言查询、汇总、分析。核心仍然是mapreduce作业。
1、它是由Facebook开源,最初用于解决海量数据结构化的日志数据统计问题,它可以作为ETL工具
2、它是构建在hadoop之上的数据仓库,相当于hadoop之上的一个客户端,可以用来存储、查询和分析存储在hadoop中的数据
3、它是一种SQL解析引擎,能够将类SQL的查询语言——HQL转换成Map/Reduce中的Job在hadoop上执行
Hive常见的应用场景
1、日志分析
1)统计网站一个时间段内的pv、uv
2)从不同维度进行数据分析
2、海量结构化数据离线分析
hive的数据存储特点
1、数据存储是基于hadoop的HDFS;
2、没有专门的数据存储格式;
3、存储结构主要有:数据库、文件(默认可以直接加载文本文件)、表、视图、索引;
说明:hive中的表实质就是HDFS的目录,按表名将文件夹分开,若是分区表,则分区值是子文件夹。这些数据可以直接在M/R中使用。hive中的数据是存放在HDFS中的。
Hive的优点
1、简单容易入手
2、它是为超大数据集而设计的计算和扩展能力
3、提供统一的元数据管理
Hive的缺点
1、Hive的HQL的表达能力有限
1)迭代式算法无法表达,比如pagerank。
2)数据挖掘方面,比如kmeans。
2、Hive的效率比较低
1)hive自动生成的MapReduce作业,通常情况下不够智能化。
2)hive调优比较困难
3)hive可控性比较差
Hive的组成部分
1、用户接口
CLI、JDBC/ODBC、WebUI
2、元数据存储(MetaStore)
默认derby数据库,真实环境一般使用mysql数据库
3、驱动器(Driver)
解释器、编译器、优化器、执行器
4、hadoop分布式集群
利用MapReducer分布式计算,利用HDFS分布式存储
用户接口
Hive 对外提供了三种服务模式,即 Hive 命令行模式(CLI),Hive 的 Web 模式(WUI),Hive 的远程服务(Client)。下面介绍这些服务的用法。
1、 Hive 命令行模式(这种方式会启动一个hive副本,是一种重量级方式)
Hive 命令行模式启动有两种方式。执行这条命令的前提是要配置 Hive 的环境变量。
1) 进入 /usr/local/hive/bin 目录,执行如下命令。
./hive2) 直接执行命令。
hive --service cli2、Hive Web 模式
Hive Web 界面的启动命令如下。
hive --service hwi通过浏览器访问 Hive,默认端口为 9999。
3、 Hive 的远程服务(建立Thrift服务器,给远程调用(jdbc\beeline) )
远程服务(默认端口号 10000)启动方式命令如下,“nohup...&” 是 Linux 命令,表示命令在后台运行
nohup hive --service hiveserver & //在Hive 0.11.0版本之前,只有HiveServer服务可用
nohup hive --service hiveserver2 & //在Hive 0.11.0版本之后,提供了HiveServer2服务Hive工作原理
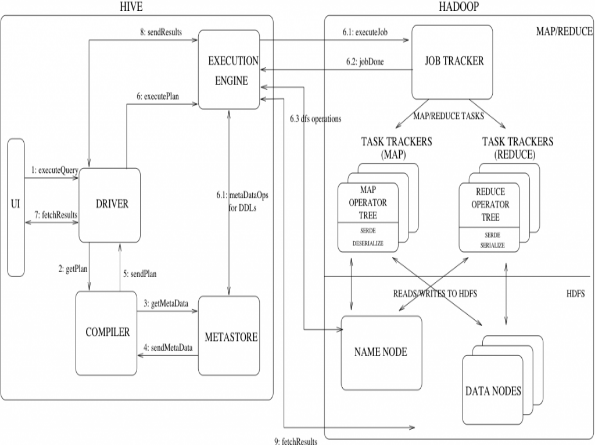
MapReduce 开发人员可以把自己写的 Mapper 和 Reducer 作为插件支持 Hive 做更复杂的数据分析。 它与关系型数据库的 SQL 略有不同,但支持了绝大多数的语句(如 DDL、DML)以及常见的聚合函数、连接查询、条件查询等操作。
Hive 不适合用于联机(online) 事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。Hive 的特点是可 伸缩(在Hadoop 的集群上动态的添加设备),可扩展、容错、输入格式的松散耦合。Hive 的入口是DRIVER ,执行的 SQL 语句首先提交到 DRIVER 驱动,然后调用 COMPILER 解释驱动, 最终解释成 MapReduce 任务执行,最后将结果返回。
解释器、编译器、优化器
Driver 调用解释器(Compiler)处理 HiveQL 字串,这些字串可能是一条 DDL、DML或查询语句。编译器将字符串转化为策略(plan)。策略仅由元数据操作 和 HDFS 操作组成,元数据操作只包含 DDL 语句,HDFS 操作只包含 LOAD 语句。对插入和查询而言,策略由 MapReduce 任务中的具有方向的非循环图(directedacyclic graph,DAG)组成,具体流程如下。
1)解析器(parser):将查询字符串转化为解析树表达式。
2)语义分析器(semantic analyzer):将解析树表达式转换为基于块(block-based)的内部查询表达式,将输入表的模式(schema)信息从 metastore 中进行恢复。用这些信息验证列名, 展开 SELECT * 以及类型检查(固定类型转换也包含在此检查中)。
3)逻辑策略生成器(logical plan generator):将内部查询表达式转换为逻辑策略,这些策略由逻辑操作树组成。
4)优化器(optimizer):通过逻辑策略构造多途径并以不同方式重写。
优化器的功能如下:
将多 multiple join 合并为一个 multi-way join;
对join、group-by 和自定义的 map-reduce 操作重新进行划分;
消减不必要的列;
在表扫描操作中推行使用断言(predicate);
对于已分区的表,消减不必要的分区;
在抽样(sampling)查询中,消减不必要的桶。此外,优化器还能增加局部聚合操作用于处理大分组聚合(grouped aggregations)和 增加再分区操作用于处理不对称(skew)的分组聚合。

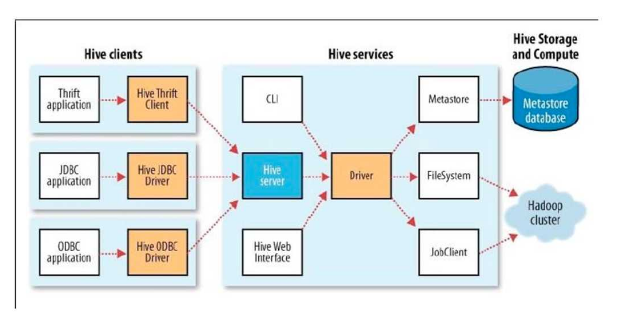
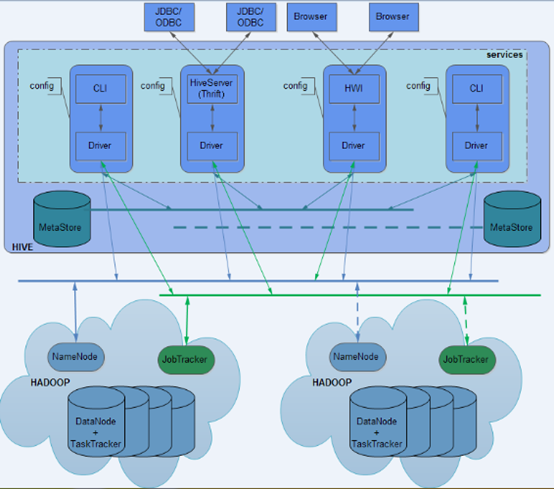
Hive的部署模式
三种安装模式
一、内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接)
二、本地模式(本地安装mysql 替代derby存储元数据)
三、远程模式(远程安装mysql 替代derby存储元数据)
一、Metastore 内嵌模式(embeded)
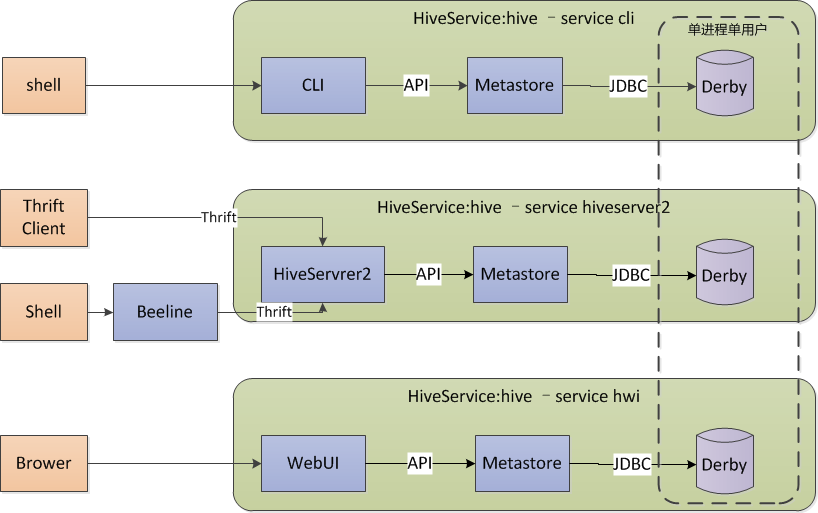
说明:
本模式使用Derby 服务器存储,能提供单进程存储服务,无法启动多个客户端(注:测试cli不能启动多个,但是使用hiveserver2可以使用多个beeline开多个会话访问),多用户时并发访问,不适合使用
Derby默认会在调用 hive 命令所在目录metastore_db持久化元数据,建议修改。
二、Metastore 本地模式(local)
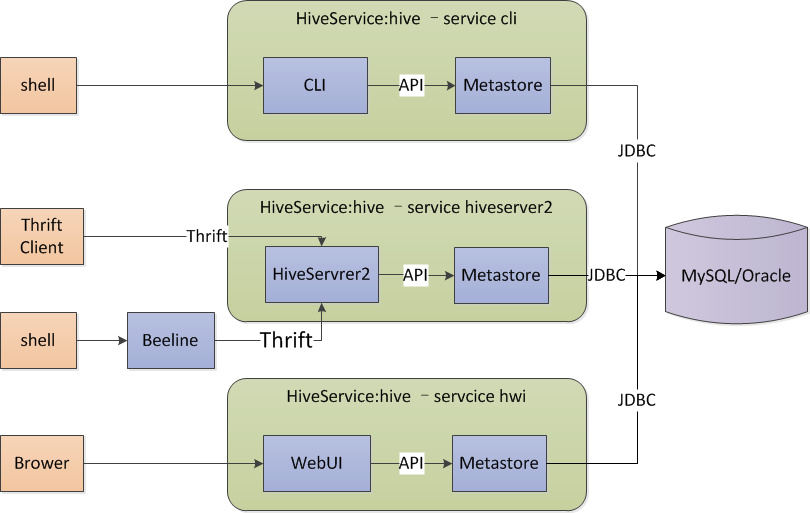
说明:
本地模式与内嵌模式最大的区别在与数据库由内嵌于hive服务变成独立本地部署,hive服务使用jdbc访问元数据,多个服务可以同时访问。
三、Metastroe 远程模式(remote)
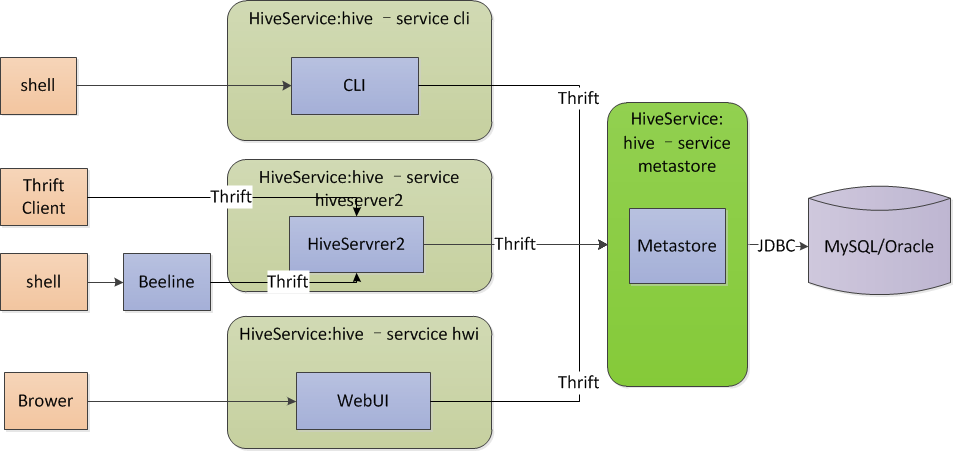
说明:
远程模式,原内嵌与hive服务的metastore服务独立出来单独运行,hive服务通过thrift访问metastore,这种模式可以控制到数据库的连接等。
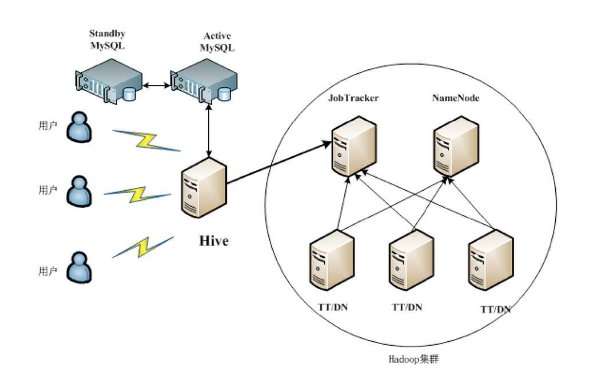
部署规划:
(1)mysql服务器
(2)元数据服务器:Metastore Server
(2)hiveserver服务器:部署hiveserver2服务,通过thrift访问metastore
其中hiveserver与Metastore Server可在同一机器上也可在两台机器上
生产环境部署图:
Hive的安装
一、Metastore 内嵌模式(embeded)
tar xf apache-hive-1.2.1-bin.tar.gz -C /usr/local# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop/cd /usr/local/hive/confvi hive-site.xml <property>
<!--hive仓库地址,会使用hadoop的fs.default.name指定的模式存储数据,这里相当于hdfs://mycluster/user/hive/warehouse -->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_embeded/warehouse</value>
</property>
<property>
<!--改属性代替hive.metastore.local为空表示嵌入模式或本地模式,否则为远程模式 -->
<name>hive.metastore.uris</name>
<value></value>
</property>
<property>
<!--JDBC URL 使用derby时可以指定metastroe存储位置,否则默认相对与命令路径 -->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=/usr/local/hive/metastore_db;create=true</value>
</property>注:cli服务只能有一个会话使用,另启动一个会话会出现连接不上metastore错误
hive> show tables;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
hive> yum install mysql-server -y GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;
flush privileges; delete from mysql.user where host != '%' and user = 'root';tar xf apache-hive-1.2.1-bin.tar.gz -C /usr/local# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop/cd /usr/local/hive/confvi hive-site.xml <configuration>
<!--表的hdfs存储地址-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_local/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<!-- mysql指定为本地 指定createDatabaseIfNotExist=true -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive_local?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- mysql 账号密码 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration> cp /usr/local/hive/lib/jline2.jar /usr/local/hadoop/share/hadoop/yarn/lib/
rm -f /usr/local/hadoop/share/hadoop/yarn/lib/jline.0.9.jarbin/hivecd /usr/local/hive/conf<configuration>
<!--表的hdfs存储地址-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!-- mysql指定为本地 指定createDatabaseIfNotExist=true -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.126.12/hive_remote?createDatabaseIfNotExist=true</value> </property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- mysql 账号密码 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration><configuration> <!--表的hdfs存储地址--> <property> <name>hive.metastore.warehouse.dir</name><value>/user/hive_remote/warehouse</value> </property> <property> <name>hive.metastore.local</name> <value>false</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.126.13:9083</value> </property> </configuration>
cp /usr/local/hive/lib/jline2.jar /usr/local/hadoop/share/hadoop/yarn/lib/
rm -f /usr/local/hadoop/share/hadoop/yarn/lib/jline.0.9.jar hive --service metastorehive上面的情况是 Metastore Server 与 Hive Server 在两台服务器上,也可以部署在同一台服务器上,只需要把两个hive-site.xml文件合并在一起就可以了
使用beeline连接Hive Server
Beeline 要与HiveServer2配合使用,支持嵌入模式和远程模式 ,jdbc方式连接
启动hive server2
./bin/hiveserver2 启动Beeline
第一种:
./bin/beeline 进入beeline命令行接口
beeline> !connect jdbc:hive2://localhost:10000
#然后回车输入用户名,注这里要写hadoop的用户,否则连接上没有hdfs操作权限,密码没有直接回车即可。
beeline> !connect jdbc:hive2://localhost:10000 username password第二种:
./bin/beeline -u jdbc:hive2://localhost:10000/default -n username -w password退出
!quit