Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点
是CDH平台首选的PB级大数据实时查询分析引擎

Impala特点
基于内存进行计算,能够对PB级数据进行交互式实时查询、分析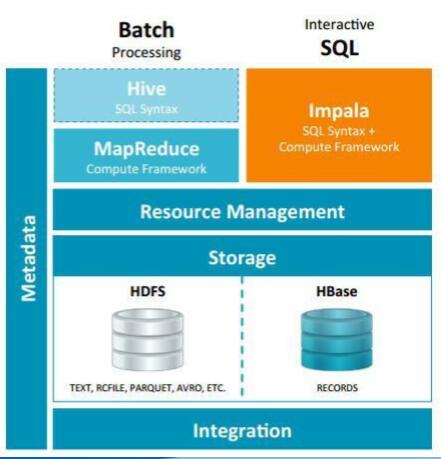
无需转换为MR,直接读取HDFS数据
C++编写,LLVM统一编译运行
兼容HiveSQL
具有数据仓库的特性, 可对hive数据直接做数据分析
支持Data Local
支持列式存储
支持JDBC/ODBC远程访问
Impala 劣势
对内存依赖大
C++编写 开源?!
完全依赖于hive
实践过程中 分区超过1w 性能严重下下降
稳定性不如hive
Impala安装
ClouderaManager
手动安装
Web查看
StateStore http://node1:25020/
Catalog http://node1:25010/
Impala核心组件
Statestore Daemon 健康检查
负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息
负责query的调度
Catalog Daemon 同步元数据信息 (impala-shell -r 外部命令 同步信息)
分发表的元数据信息到各个impalad中
接收来自statestore的所有请求
Impala Daemon 执行计算节点
接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
子节点上的守护进程,负责向statestore保持通信,汇报工作
Impala (使用hive的元数据) (使用内存计算)
Impala Shell
外部命令
-h ( -- help ) 帮助
-v ( -- version ) 查询版本信息
-V ( -- verbose ) 启用详细输出
--quiet 关闭详细输出
-p 显示执行计划
-i hostname ( -- impalad=hostname ) 指定连接主机 格式 hostname : port 默认端口 21000
-r ( -- refresh_after_connect )刷新所有元数据
-q query ( -- query=query ) 从命令行执行查询,不进入impala-shell
-d default_db ( -- database=default_db ) 指定数据库
-B(--delimited)去格式化输出
--output_delimiter=character 指定分隔符
--print_header 打印列名
-f query_file(--query_file=query_file)执行查询文件,以分号分隔
-o filename ( -- output_file filename ) 结果输出到指定文件
-c 查询执行失败时继续执行
-k ( -- kerberos ) 使用kerberos安全加密方式运行impala-shell
-l 启用LDAP认证
-u 启用LDAP时,指定用户名
特殊用法:
help
connect <hostname:port> 连接主机,默认端口21000
refresh <tablename> 增量刷新元数据库
invalidate metadata 全量刷新元数据库
explain <sql> 显示查询执行计划、步骤信息
set explain_level 设置显示级别(0,1,2,3)
shell <shell> 不退出impala-shell执行Linux命令
profile (查询完成后执行) 查询最近一次查询的底层信息
SQL
添加分区方式
1、partitioned by 创建表时,添加该字段指定分区列表
2、使用alter table 进行分区的添加和删除操作
create table t_person(id int, name string, age int) partitioned by (type string);
alter table t_person add partition (sex=‘man');
alter table t_person drop partition (sex=‘man');
alter table t_person drop partition (sex=‘man‘,type=‘boss’);分区内添加数据
insert into t_person partition (type='boss') values (1,’zhangsan’,18),(2,’lisi’,23)
insert into t_person partition (type='coder') values (3,wangwu’,22),(4,’zhaoliu’,28),(5,’tianqi’,24)查询指定分区数据
select id,name from t_person where type=‘coder’支持数据类型
–INT
–TINYINT
– SMALLINT
– BIGINT
– BOOLEAN
– CHAR
– VARCHAR
– STRING
– FLOAT
– DOUBLE
– REAL
– DECIMAL
– TIMESTAMP
CDH5.5版本以后 支持以下类型:
– ARRAY
– MAP
– STRUCT
– Complex
此外,Impala不支持HiveQL以下特性:
1、可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes
2、XML、JSON函数
3、某些聚合函数:
covar_pop, covar_samp, corr, percentile, percentile_approx, histogram_numeric, collect_set
Impala仅支持:AVG,COUNT,MAX,MIN,SUM
4、多Distinct查询
5、HDF、UDAF
以下语句:
ANALYZE TABLE (Impala:COMPUTE STATS)、DESCRIBE COLUMN、 DESCRIBE DATABASE、EXPORT TABLE、
IMPORT TABLE、SHOW TABLE EXTENDED、SHOW INDEXES、SHOW COLUMNS、
创建数据库
create database db1;
use db1;删除数据库
use default;drop database db1;创建表(内部表)
默认方式创建表:
create table t_person1(
id int,
name string
)指定存储方式:
create table t_person2(
id int,
name string
)
row format delimited
fields terminated by ‘\0’ (impala1.3.1版本以上支持‘\0’ )
stored as textfile;其他方式创建内部表
使用现有表结构
create table tab_3 like tab_1;指定文本表字段分隔符
alter table tab_3 set serdeproperties (‘serialization.format’=‘,’,’field.delim’=‘,’);插入数据
直接插入值方式
insert into t_person values (1,hex(‘hello world’));从其他表插入数据:
insert (overwrite) into tab_3 select * form tab_2 ; 批量导入文件方式方式
load data local inpath ‘/xxx/xxx’ into table tab_1;
创建表(外部表)
默认方式创建表
create external table tab_p1(
id int,
name string
)
location ‘/user/xxx.txt’指定存储方式
create external table tab_p2 like parquet_tab
‘/user/xxx/xxx/1.dat’
partition (year int , month tinyint, day tinyint)
location ‘/user/xxx/xxx’ • stored as parquet;视图
创建视图
create view v1 as select count(id) as total from tab_3 ;查询视图:
select * from v1;查看视图定义:
describe formatted v1注意:
1)不能向impala的视图进行插入操作
2)insert 表可以来自视图
数据文件处理
加载数据:
1、insert语句:插入数据时每条数据产生一个数据文件,不建议用此方式 加载批量数据
2、load data方式:在进行批量插入时使用这种方式比较合适
3、来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写 入新的表生产少量的数据文件。
也可以通过此种方式进行格式转换。
空值处理:
impala将“\n”表示为NULL,在结合sqoop使用是注意做相应的空字段 过滤,
也可以使用以下方式进行处理: • alter table name set tblproperties (“serialization.null.format”=“null”)
代码
Impala可以通过Hive外部表方式和HBase进行整合,步骤如下:
步骤1:创建hbase 表,向表中添加数据
create 'test_info', 'info' – put 'test_info','1','info:name','zhangsan'
put 'test_info','2','info:name','lisi'步骤2:创建hive表
CREATE EXTERNAL TABLE test_info(key string,name string )
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,info:name")
TBLPROPERTIES – ("hbase.table.name" = "test_info");步骤3:刷新Impala表
invalidate metadatajdbc
配置:
impala.driver=org.apache.hive.jdbc.HiveDriver
impala.url=jdbc:hive2://node2:21050/;auth=noSasl
impala.username=
impala.password=尽量使用PreparedStatement执行SQL语句
1.性能上PreparedStatement要好于Statement
2.Statement存在查询不出数据的情况
Impala 性能优化
要点:
1、SQL优化,使用之前调用执行计划列出需要完成这一项查询的 详细方案,explain sql、profile
2、选择合适的文件格式进行存储
3、避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间 表)
4、使用合适的分区技术,根据分区粒度测算
5、使用compute stats进行表信息搜集
6、网络io的优化:
a.避免把整个数据发送到客户端
b.尽可能的做条件过滤
c.使用limit字句
d.输出文件时,避免使用美化输出
7、使用profile输出底层信息计划,在做相应环境优化