资源调度:
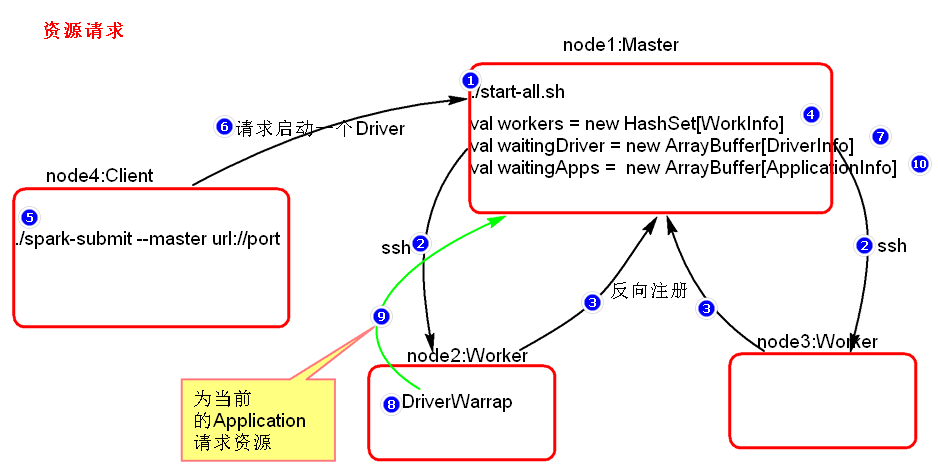
资源请求简单图:
// Worker 的 hostname、core数、mem内存
val workers = new HashSet[WorkerInfo]
val idToApp = new HashMap[String, ApplicationInfo]
// Application信息,其中 包括每个Executor的要使用的资源情况 (Core数、Mem内存大小)、application总共使用的资源情况 (Core数、Mem内存大小)
val waitingApps = new ArrayBuffer[ApplicationInfo]
val apps = new HashSet[ApplicationInfo]
private val idToWorker = new HashMap[String, WorkerInfo]
private val addressToWorker = new HashMap[RpcAddress, WorkerInfo]
private val endpointToApp = new HashMap[RpcEndpointRef, ApplicationInfo]
private val addressToApp = new HashMap[RpcAddress, ApplicationInfo]
private val completedApps = new ArrayBuffer[ApplicationInfo]
private var nextAppNumber = 0
private val drivers = new HashSet[DriverInfo]
private val completedDrivers = new ArrayBuffer[DriverInfo]
// Drivers currently spooled for scheduling 包括 Jar包路径、Driver进程所需的资源信息
private val waitingDrivers = new ArrayBuffer[DriverInfo]
private var nextDriverNumber = 0
A: Worker启动时会向Master注册,汇报 Worker 的 hostname、core数、mem内存
Master会将这些信息存储在 val workers = new HashSet[WorkInfo]() 中
B:客户端向Master请求启动一个Driver进程,其中包括 Jar包路径、Driver进程所需的资源信息
Master会将这些信息存储在 val waitingDrivers = new ArrayBuffer [DriverInfo]() 中
C:Driver中的TaskScheduler向Master注册Application信息,其中 包括每个Executor的要使用的资源情况 (Core数、Mem内存大小)、application总共使用的资源情况 (Core数、Mem内存大小)
Master会根据这些信息算出executor个数,然后将这些信息存储在 val waitingApps = ArrayBuffer [ApplicationInfo]() 中
schedule() 方法
schedule在每次新的app提交来,或worker节点资源变化时都会执行
用来遍历等待启动的Driver,然后将Driver分配到满足Driver资源要求的Worker节点上,再通过endpoint消息通知对应的Worker启动Driver
然后再在 startExecutorsOnWorkers() 方法中分配Executor到在Worker上,并发送消息让Worker启动。
/**
* schedule在每次新的app提交来,或worker节点变化时都会执行
* Schedule the currently available resources among waiting apps. This method will be called
* every time a new app joins or resource availability changes.
*/
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) { return } //如果是恢复模式直接结束
// Drivers take strict precedence over executors
//workers代表的是集群刚启动的时候worker向master注册的信息。这里面将workers打散。
val shuffledWorkers = Random.shuffle(workers) // Randomization helps balance drivers
for (worker <- shuffledWorkers if worker.state == WorkerState.ALIVE) { //遍历alive的worker
//waitingDriver实际上是指Driver向master注册时的信息。这种情况是在cluster模式下。
for (driver <- waitingDrivers) {
//对于Driver来说资源上是指mem和core ,if条件里面判断的时候Driver所需要的内存和core
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
//这个方法传入的两个参数是:worker:Driver所要运行的位置 driver:当前Driver的信息:SparkContext(各种任务调度器)
launchDriver(worker, driver)
//将Driver启动完成后,需要从等待队列中删除此Driver
waitingDrivers -= driver
}
}
}
//这里面是给作业分配资源。对于作业来说资源指? Executor
startExecutorsOnWorkers()
}
// master通过endpoint 向Worker发送消息,启动Driver进程。
private def launchDriver(worker: WorkerInfo, driver: DriverInfo) {
logInfo("Launching driver " + driver.id + " on worker " + worker.id)
worker.addDriver(driver)
driver.worker = Some(worker)
//endpoint:消息循环体,发送消息接受消息
worker.endpoint.send(LaunchDriver(driver.id, driver.desc))
driver.state = DriverState.RUNNING
}startExecutorsOnWorkers()
根据 coresPerExecutor 每个Executor需要的Cores数 和 usableWorkers 可用的Worker
在 scheduleExecutorsOnWorkers() 方法中计算出每个Worker分配的Cores数,Executor数
然后在 allocateWorkerResourceToExecutors() 方法中通知Worker启动这些Executor
/**
* 分配Executor到Worker中,其中要计算每个Worker分配的Executor数
* 并通知Worker启动
* Schedule and launch executors on workers
*/
private def startExecutorsOnWorkers(): Unit = {
// Right now this is a very simple FIFO scheduler. We keep trying to fit in the first app in the queue, then the second app, etc.
// waitingApps代表的是所有向master注册的作业
for (app <- waitingApps if app.coresLeft > 0) {
/**
* 指定Executor的规格,这里指定的是Executor的core的个数 --executor-cores 3 每个Executor使用多少个core
* spark-submit --master spark:// --total-executor-cores 10 所有的Executor一共使用10 --executor-cores 4 每一个Executor使用4个core --executor-memory 每一个Executor使用内存大小
*/
val coresPerExecutor: Option[Int] = app.desc.coresPerExecutor
/**
* Filter out workers that don't have enough resources to launch an executor
* coresPerExecutor他的值怎么设置? --executor-cores
* memoryPerExecutorMB : --executor-memory
*/
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
.filter(worker => worker.memoryFree >= app.desc.memoryPerExecutorMB && //再检查一次Worker是否满足App的要求
worker.coresFree >= coresPerExecutor.getOrElse(1)) // coresPerExecutor没有设置就设置为1
.sortBy(_.coresFree).reverse
// 通过此方法产生,根据配置的分配算法Executor到Worker中,返回一个数组
// 数组,下标代表Worker,值代表该Worker分配的Core数
val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers, spreadOutApps)
// Now that we've decided how many cores to allocate on each worker, let's allocate them
// 正式发送endpoint消息到Worker中启动对应的Executor
for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
allocateWorkerResourceToExecutors(
app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))
}
}
}scheduleExecutorsOnWorkers() :
两种分配方式:
第一种尽可能的给每个App的Exector分配到尽可能 多 的Worker中 (即 轮询方式 ),这个为默认,有利于数据本地化
第二种尽可能的给每个App的Exector分配到尽可能 少 的Worker中
分配给每个Executor的Core数可以配置, --executor-cores
如果配置了 App就可以在一个Worker上启动多个Executor,但是Executor个数还受到 Worker分配的内存大小限制。
如果没有配置,一个Worker上对于这个App只会启动一个executor,这个executor会使用这个Worker的所有资源
注释中有一个例子来说明配置 每个Executor的Core数 的重要性
如果不配置,那么有些特殊情况下,在轮询分配时即有足够的资源,仍然启动不起来Executor
/**
* 将executors分配到Worker中
* Schedule executors to be launched on the workers.
* Returns an array containing number of cores assigned to each worker.
*
* 两种分配方式:
* 第一种尽可能的给每个App的Exector分配到尽可能多的Worker中 ,这个为默认
* 第二种尽可能的给每个App的Exector分配到尽可能少的Worker中
* 第一种更有利于数据本地化
* There are two modes of launching executors. The first attempts to spread out an application's
* executors on as many workers as possible, while the second does the opposite (i.e. launch them
* on as few workers as possible). The former is usually better for data locality purposes and is
* the default.
*
* 分配给每个Executor的Core数可以配置,如果配置了 App就可以在一个Worker上启动多个Executor
* 如果没有配置,一个Worker上对于这个App只会启动一个executor,这个executor会使用这个Worker的所有资源
* The number of cores assigned to each executor is configurable. When this is explicitly set,
* multiple executors from the same application may be launched on the same worker if the worker
* has enough cores and memory. Otherwise, each executor grabs all the cores available on the
* worker by default, in which case only one executor may be launched on each worker.
*
* 一个例子来说明配置 每个Executor的Core数 的重要性
* 如果不配置,那么有些特殊情况下,在轮询分配时即有足够的资源,仍然启动不起来Executor
* It is important to allocate coresPerExecutor on each worker at a time (instead of 1 core
* at a time). Consider the following example: cluster has 4 workers with 16 cores each.
* User requests 3 executors (spark.cores.max = 48, spark.executor.cores = 16). If 1 core is
* allocated at a time, 12 cores from each worker would be assigned to each executor.
* Since 12 < 16, no executors would launch [SPARK-8881].
* spark-submit --master
*/
private def scheduleExecutorsOnWorkers(
app: ApplicationInfo,
usableWorkers: Array[WorkerInfo],
spreadOutApps: Boolean): Array[Int] = {
//每一个Executor的core个数
val coresPerExecutor = app.desc.coresPerExecutor
//每一个Executor所需要的core的最少个数,没有配置就是1 --executor-cores
val minCoresPerExecutor = coresPerExecutor.getOrElse(1)
//--executor-cores 没有设置的话,这个永远为true
val oneExecutorPerWorker = coresPerExecutor.isEmpty
//每一个Executor所需要的内存 默认1G
val memoryPerExecutor = app.desc.memoryPerExecutorMB
//可用的worker的个数
val numUsable = usableWorkers.length
// 数组,下标代表Worker,值代表该Worker分配的Core数
val assignedCores = new Array[Int](numUsable) // Number of cores to give to each worker
// 数组,下标代表Worker,值代表该Worker分配的executors数
val assignedExecutors = new Array[Int](numUsable) // Number of new executors on each worker
//application还需要的cores的个数与集群剩余可用的个数 取最小值
//代表App申请的总核数
var coresToAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
/**
* Return whether the specified worker can launch an executor for this app.
* canLaunchExecutor 主要是过滤这些Worker的资源是否满足分配Executor的条件
* */
def canLaunchExecutor(pos: Int): Boolean = {
val keepScheduling = coresToAssign >= minCoresPerExecutor
val enoughCores = usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor
// If we allow multiple executors per worker, then we can always launch new executors.
// Otherwise, if there is already an executor on this worker, just give it more cores.
val launchingNewExecutor = !oneExecutorPerWorker || assignedExecutors(pos) == 0
if (launchingNewExecutor) {
val assignedMemory = assignedExecutors(pos) * memoryPerExecutor
val enoughMemory = usableWorkers(pos).memoryFree - assignedMemory >= memoryPerExecutor
val underLimit = assignedExecutors.sum + app.executors.size < app.executorLimit
keepScheduling && enoughCores && enoughMemory && underLimit
} else {
// We're adding cores to an existing executor, so no need
// to check memory and executor limits
keepScheduling && enoughCores
}
}
// Keep launching executors until no more workers can accommodate any
// more executors, or if we have reached this application's limits
var freeWorkers = (0 until numUsable).filter(canLaunchExecutor) // 再次过滤
while (freeWorkers.nonEmpty) {
freeWorkers.foreach { pos =>
var keepScheduling = true
while (keepScheduling && canLaunchExecutor(pos)) {
coresToAssign -= minCoresPerExecutor // 将申请的总核数的Cores减1
assignedCores(pos) += minCoresPerExecutor // 将对应Worker已经分配的Cores加一个Executor需要的Core数
/**
* If we are launching one executor per worker, then every iteration assigns 1 core
* to the executor. Otherwise, every iteration assigns cores to a new executor.
*/
if (oneExecutorPerWorker) { //如果没配置--executor-cores,那一个Worker只分配一个executor
assignedExecutors(pos) = 1
} else {
assignedExecutors(pos) += 1 //配置了则每次循环多一个Executor
} // 这里计算每个Worker分配的Executor个数的目的是,因为每个Executor还配置需要的内存,
// 根据个数在canLaunchExecutor方法中来计算Worker是否有需要的内存
/**
* Spreading out an application means spreading out its executors across as
* many workers as possible. If we are not spreading out, then we should keep
* scheduling executors on this worker until we use all of its resources.
* Otherwise, just move on to the next worker.
* 如果配置的是轮询启动,那接下来停止循环,那下一个Worker先分配,这样就将Exector平均的分配到了各个Worker中,
* 如果不是轮询,那么就在当前的Worker上将Executor分配完,这样尽可能的将Executor分配到少的Worker中
*/
if (spreadOutApps) {
keepScheduling = false
}
}
}
// 过滤掉没可用资源的Worker
freeWorkers = freeWorkers.filter(canLaunchExecutor)
}
//返回数组
assignedCores
}allocateWorkerResourceToExecutors() :
Executor的个数:
每个Worker根据分配的Core数 /每个Executor配置的Cores数来计算Executor的个数 , 没有配置就设置为一个Executor。
其实在scheduleExecutorsOnWorkers()中的assignedExecutors已经计算出来了,不懂为什么这么还计算一遍?
Executor的Core数:
从配置 --executor-cores 中获取,没有就这一个Executor占有这个Work分配的全部Cores
发送Endpoint消息给Worker启动Executors
/**
* Allocate a worker's resources to one or more executors.
* @param app the info of the application which the executors belong to
* @param assignedCores number of cores on this worker for this application
* @param coresPerExecutor number of cores per executor
* @param worker the worker info
*/
private def allocateWorkerResourceToExecutors(
app: ApplicationInfo,
assignedCores: Int, // 该Worker被分配的Core数
coresPerExecutor: Option[Int],
worker: WorkerInfo): Unit = {
// If the number of cores per executor is specified, we divide the cores assigned
// to this worker evenly among the executors with no remainder.
// Otherwise, we launch a single executor that grabs all the assignedCores on this worker.
// 根据分配的Core数/每个Executor配置的Cores数来计算Executor的个数 , 没有配置就设置为一个Executor
val numExecutors = coresPerExecutor.map { assignedCores / _ }.getOrElse(1)
// 没有配置每个Executor配置的Cores, 就让这个Executor使用分配的全部的Cores
val coresToAssign = coresPerExecutor.getOrElse(assignedCores)
for (i <- 1 to numExecutors) {
val exec = app.addExecutor(worker, coresToAssign)
launchExecutor(worker, exec) //启动Executors
app.state = ApplicationState.RUNNING
}
}总结:资源调度源码结论
1、在提交application的时候,如果没有指定 --executor-cores 这个选项的话,那么在每一个Worker上只会启动一个Executor,并且这个Executor会使用这个Worker管理的所以core。
2、如果想在一个worker上启动多个Executor,需要在Application的时候使用 --executor-cores 这个选项指定每个Executor使用的core数,并可以使用 --total-executor-cores 进一步限制 Executor 的个数。资源不足时除了考虑Core数,还要考虑节点Mem内存
3、spreadOutApps 这个参数可以决定Executor的启动方式,默认为ture,Executor的启动方式为轮询启动,这在一定程度上有利于数据本地化。
--driver-memory
Driver程序使用内存大小(例如:1000M,5G),默认1024M
--executor-memory
每个executor内存大小(如:1000M,2G),默认1G
Spark standalone with cluster deploy mode only:
--driver-cores
Driver程序的使用core个数(默认为1),仅限于Spark alone模式
Spark standalone or Mesos with cluster deploy mode only:
--supervise
失败后是否重启Driver,仅限于Spark alone或者Mesos模式
Spark standalone and Mesos only:
--total-executor-cores
executor使用的总核数,仅限于Spark Alone、Spark on Mesos模式
Spark standalone and YARN only:
--executor-cores
每个executor使用的core数,Spark on Yarn默认为1,standalone默认为worker上所有可用的core。
YARN-only:
--driver-cores
driver使用的core,仅在cluster模式下,默认为1。
--queue
QUEUE_NAME 指定资源队列的名称,默认:default
--num-executors
一共启动的executor数量,默认是2个。
任务调度:
在Spark中作业调度的相关类最重要的就是DAGScheduler,DAGScheduler顾名思义就是基于DAG图的Scheduler
DAG全称 Directed Acyclic Graph,有向无环图。简单的来说,就是一个由顶点和有方向性的边构成的图中,从任意一个顶点出发,没有任何一条路径会将其带回到出发的顶点。
在作业调度系统中,调度的基础就在于判断多个作业任务的依赖关系,这些任务之间可能存在多重的依赖关系,也就是说有些任务必须先获得执行,然后另外的相关依赖任务才能执行,但是任务之间显然不应该出现任何直接或间接的循环依赖关系,所以本质上这种关系适合用DAG有向无环图来表示。
概括地描述DAGScheduler和TaskScheduler 的功能划分就是:
DAGScheduler负责将作业拆分成不同阶段的具有依赖关系的多批任务,可以理解为DAGScheduler负责任务的 逻辑调度。
TaskScheduler 负责实际每个具体任务的 物理调度
任务调度可以从一个Action类算子开始。因为Action类算子会触发一个job的执行。
/**
* Return the number of elements in the RDD.
* action算子是会触发一个Job
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum不断点击 sc.runJob()方法,直到这个下面这个 sc.runJob():
这里面调用了 dagScheduler.runJob() ;
还处理了checkpoint标记;
/**
* Run a function on a given set of partitions in an RDD and pass the results to the given
* handler function. This is the main entry point for all actions in Spark.
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
/**
* 中间代码省略
*/
// dagScheduler提交了Job
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
// Checkpoint 是遇到action算子就会触发
// 此处就是执行往前回溯,寻找执行checkpoint标记
rdd.doCheckpoint()
}rdd action —> sparkContext.runJob —> dagscheduler.runJob
进入 dagScheduler.runJob(),再进去 dagScheduler.submitJob() : 最后一行
// eventProcessLoop: DAGSchedulerEventProcessLoop
// DAGSchedulerEventProcessLoop extends EventLoop
// EventLoop.post()
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))eventProcessLoop 为 DAGSchedulerEventProcessLoop,post()方法是其 父类EventLoop 的方法:
EventLoop 为事件循环处理器,顾名思义就是为了处理事件 ,队列存储事件然后再交给对应的类处理
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]() //存储事件的队列 /**
* Put the event into the event queue. The event thread will process it later.
*/
def post(event: E): Unit = {
// 往任务队列里添加了此Job
eventQueue.put(event)
}也就是说 eventProcessLoop.post() 方法,是往 eventQueue队列 添加了一个 JobSubmitted 对象 ,
EventLoop 里 还有一个 eventThread 线程,死循环去取 队列里的对象 , 交给 onReceive(event)
// eventThread 线程,死循环去取 队列里的对象 , 交给 onReceive(event)
private val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event) // 为子类DAGSchedulerEventProcessLoop实现的方法
} catch {
// 。。。省略onReceive(event) 为子类 DAGSchedulerEventProcessLoop 实现的方法 ,而 onReceive(event) 调用了 doOnReceive(event)
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
// 模式匹配上了 JobSubmitted , 调用了dagScheduler.handleJobSubmitted()
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)方法里 事件event 模式匹配上了 JobSubmitted , 进入 dagScheduler.handleJobSubmitted() 方法
首先将 action算子传进来的 finalRDD 封装成一个 stage,
(为什么只需要finalRDD就能代表stage呢? 因为RDD里保存了依赖关系,所以只要finalRDD就可以了 )
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
// 将action算子触发的 finalRDD , 封装成一个stage,
// 为什么只需要finalRDD就能代表stage呢? 因为RDD里保存了依赖关系,所以只要finalRDD就可以了
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite) 然后将 finalStage 传给了 submitStage() 方法
这是一个迭代方法,不断迭代通过 getMissingParentStages() 方法 寻找 finalStage的所有依赖的 父stage ,父stage迭代寻找依赖的父父stage
也就是 DAGScheduler 在这个寻找的过程中,完成了stage的划分。
然后将找的所有依赖父stage 依次传入调用 submitMissingTasks() 方法
/**
* Submits stage, but first recursively submits any missing parents
* 迭代方法,不断迭代寻找 finalStage的所有依赖的 父stage,父stage依赖的父stage
* 然后将父爷stage传入 submitMissingTasks()方法
*/
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 获取该依赖的 父stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) { // 直到没有发现父stage了,
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get) // 就提交这些父stage
} else {
for (parent <- missing) { //如果有父stage就再次迭代此方法查找 此父stage的父stage
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}getMissingParentStages() :
这个方法找到该传入的stage所依赖的所有父stage
负责得到传入的stage依赖的父stage们
/**
* 从触发action算子的RDD的依赖开始往前寻找,
* 遇到窄依赖RDD,就继续查看这个RDD的它的依赖是否是shuffle依赖
* 遇到shuffle依赖,就将这个依赖RDD定义为一个stage,
* 也就是说这个方法负责得到传入的stage依赖的父stage们
*/
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage] // 保存父stage
val visited = new HashSet[RDD[_]] // 保存遍历过的RDD
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]] //定义了一个栈
//定义方法: 查找父 stage
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd // 将遍历过的rdd保存到visited里
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) { //遍历此RDD的依赖
dep match { //匹配
case shufDep: ShuffleDependency[_, _, _] => // 如果与依赖的RDD是宽依赖 (shuffle依赖)
val mapStage = getShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage // 那么 将这个依赖的RDD,定义为一个stage, 并添加父stage里
}
case narrowDep: NarrowDependency[_] => // 如果与依赖的RDD是窄依赖
waitingForVisit.push(narrowDep.rdd) // 那将此RDD,添加到 栈里,等待下次弹出调用visit(),
// 再寻找 此依赖RDD的依赖RDD,看是否是一个shuffle依赖(构成一个Stage)
}
}
}
}
}
// 第一次执行,将finalStage的rdd压入栈
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop()) //遍历栈,第一次执行将弹出finalStage传入visit()方法
}
missing.toList
}submitStage() 方法将 每个stage依次传入 调用 submitMissingTasks() 方法:
首先会遍历这个stage的partition,每个partition返回一个task对象,
如果是 shuffle Write 端 , 返回 ShuffleMapTask , 如果不是, 返回 ResultTask
// 得到这个stage的 tasks val tasks: Seq[Task[_]] = try { stage match { case stage: ShuffleMapStage => //如果stage是shuffle依赖,每个partition创建一个ShuffleMapTask partitionsToCompute.map { id => val locs = taskIdToLocations(id) val part = stage.rdd.partitions(id) new ShuffleMapTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, stage.internalAccumulators) } case stage: ResultStage => //如果stage如果不是, 则每个partition创建一个ResultTask , ResultTask 会将计算结果返回到driver端 val job = stage.activeJob.get partitionsToCompute.map { id => val p: Int = stage.partitions(id) val part = stage.rdd.partitions(p) val locs = taskIdToLocations(id) new ResultTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, id, stage.internalAccumulators) } }
DAGScheduler 将传入的这个stage的一堆task 封装到 taskSet对象 里 , 然后传给了 taskScheduler 的 submitTasks() 的方法
// DAGScheduler 将这个stage的一堆task封装到taskSet对象里
// 然后调用taskScheduler.submitTasks()的方法
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))taskScheduler 为一个 trait , 其实现类为 TaskSchedulerImpl ,进入该类查看 submitTasks() 的方法 , 最后一行:
backend.reviveOffers() var backend: SchedulerBackend = null backend 是调用 initialize(backend: SchedulerBackend) 初始化的
initialize() 中 还会设置task的调度规则
/**
* 这个方法在什么时候调用呢?
* 是在 new SparkContext()的时候, Driver端初始化的
*/
def initialize(backend: SchedulerBackend) {
this.backend = backend // 传入
// temporarily set rootPool name to empty
// TaskSchedulerImpl在初始化过程中会根据用户设定的SchedulingMode(默认为FIFO)创建一个rootPool根调度池
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match { /
case SchedulingMode.FIFO =>
// 先进先出型: FIFO Pool直接管理的是TaskSetManager,
// 根据StageID的顺序来调度TaskSetManager
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
// 公平调度:FAIR Pool管理的对象是下一级的POOL,子调度池进一步管理属于该调度池的TaskSetManager
// 根据所管理的Pool/TaskSetManager中正在运行的任务的数量来判断优先级
new FairSchedulableBuilder(rootPool, conf)
}
} // pool -> SchedulableBuilder对象
// buildPools rootPool的基础上完成整个Pool的构建工作
schedulableBuilder.buildPools()
}这个方法在什么时候调用呢? 是在 new SparkContext() 的时候, Driver端初始化的
进入到 SparkContext 类中 : 找到 TaskScheduler 和 DAGScheduler 实例化的地方
// 这段代码在类体内,所以在new SparkContext()时就会执行
// Create and start the scheduler master : master的url : spark://node01:7077
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
_schedulerBackend = sched
_taskScheduler = ts
// 创建DAGScheduler
_dagScheduler = new DAGScheduler(this)进入 createTaskScheduler() 方法 :
基于 master URL 创建 task scheduler , 找到匹配 Spark:// 的
/** * 基于master URL创建task scheduler * Create a task scheduler based on a given master URL. * Return a 2-tuple of the scheduler backend and the task scheduler. */ private def createTaskScheduler( // 省略 //正则匹配 master match { // 省略 // 配置 spark: // case SPARK_REGEX(sparkUrl) => val scheduler = new TaskSchedulerImpl(sc) //新建TaskSchedulerImpl val masterUrls = sparkUrl.split(",").map("spark://" + _) // 找到backend的实例化地方 val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls) //调用 initialize方法 scheduler.initialize(backend) (backend, scheduler) // 省略
所以此时终于找到了 backend 为 SparkDeploySchedulerBackend , 也就是
taskScheduler.submitTasks() 方法调用了 backend.reviveOffers() , 即SparkDeploySchedulerBackend 中的 reviveOffers() 方法 ,进入:
发现 reviveOffers() 为 SparkDeploySchedulerBackend 继承自 CoarseGrainedSchedulerBackend 的方法:
Coarse Grained Scheduler 顾名思义,即粗粒度的调度器 ,
官方注释 : 这个粗粒度调度器负责与executor通信
(spark-1.6 开始使用 netty 通信,之前是scala的Akka的Actor ,为了 兼容 ,spark 用netty实现了 Actor 相同的接口)
/**
* 这个粗粒度调度器负责与executor通信
* 这个调度器会一开始就给Job分配好所有的Exector,而不是等task执行完再申请新的Executor
* A scheduler backend that waits for coarse grained executors to connect to it through Akka.
* This backend holds onto each executor for the duration of the Spark job rather than relinquishing
* executors whenever a task is done and asking the scheduler to launch a new executor for
* each new task.
*/
class CoarseGrainedSchedulerBackend(scheduler: TaskSchedulerImpl, val rpcEnv: RpcEnv)查看 CoarseGrainedSchedulerBackend .reviveOffers() 方法:
override def reviveOffers() {
// driverEndpoint 相当于driver 的邮箱
// 这里是向 driver邮箱发送ReviveOffers 这封信
driverEndpoint.send(ReviveOffers)
}driverEndpoint: RpcEndpointRef 消息循环体
Endpoint其实是使用netty传输的,不是 Akka Actor , RpcEndpointRef 类似 ActorRef ,定义了相同的接口
通过这个对象即可以发消息,也可以收消息, 找到receive方法即可收到发送的这条方法:
driverEndpoint 在 start() 方法里实例化 , start() :
override def start() {
//省略
// TODO (prashant) send conf instead of properties
driverEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint(properties))
}
protected def createDriverEndpoint(properties: Seq[(String, String)]): DriverEndpoint = {
new DriverEndpoint(rpcEnv, properties)
}进入 DriverEndpoint 中,找到 receive () 方法, 发现收到 ReviveOffers , 调用了 makeOffers()
override def receive: PartialFunction[Any, Unit] = {
// 省略
case ReviveOffers =>
makeOffers()
makeOffers() 调用了 launchTasks(scheduler.resourceOffers(workOffers)) :
SchedulerBackend 将task序列化,发送一个 LaunchTask消息 executor 的邮箱
为什么要交给 backend 发送task,不直接由 taskScheduler发送呢 ?
因为基于不同的部署方式有不同的backend( local,standalone,yarn ),而是发送endpoint消息可以异步通信
// executorData 中保存着 executor启动后反向注册给 taskScheduler 的值 ,邮箱地址
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK // Executor可用的Cores数 减去 这个task需要的core数
// 将task序列化,发送一个 LaunchTask消息 到executor的邮箱
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
而 Executor接收邮件的类 为 CoarseGrainedExecutorBackend
找到 receive() 方法 , 其中的 LaunchTask :
将 task 反序列化, 传给 executor.launchTask()
// taskScheduler 发来的 LaunchTask
case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
System.exit(1)
} else {
// 反序列化 task
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
// 调用
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}进入 executor.launchTask() :
将task封装成线程, 添加到线程池中执行
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
// TaskRunner 继承自 Runnable
// 这里将task封装成一个线程
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr) // 将taskId添加到已运行taskMap中
threadPool.execute(tr) // 将此task线程添加到线程池中执行
}任务调度总结:
一、运行方式
App对应的 DAGScheduler在SparkContext初始化过程中实例化
DAGScheduler的事件循环逻辑基于 netty 的消息传递机制来构建:
在DAGScheduler的Start函数中创建了一个 SparkDeploySchedulerBackend
SparkDeploySchedulerBackend 继承自 CoarseGrainedSchedulerBackend , 使用 netty实现的RpcEndpoint 进行线程间通信
spark-1.6 开始使用 netty ,之前是scala的Akka的Actor (eventProcessActor) ,为了 兼容 ,spark 用netty实现了Actor相同的接口
用来处理各种DAGSchedulerEvent,这些事件包括作业的提交,任务状态的变化,监控等等
Client和TaskScheduler 与 DAGScheduler 的交互方式:
spark1.6之前是通过DAGScheduler暴露的函数接口间接的给 eventProcessActor 发送相关Actor消息 。
spark1.6是构建了 EventProcessLoop 对象,调用的事件都存在EventProcessLoop里的队列里,顺序执行。
DAGScheduler作业调度的两个主要入口是 runJob 和 submitJob:
runJob在内部调用submitJob,阻塞等待直到作业完成(或失败)
submitJob 返回一个Jobwaiter对象,可以用在异步调用中,通过 Jobwaiter对象用来判断作业完成或者取消作业;
具体往DAGScheduler提交作业的操作,基本都是封装在RDD的相关Action操作里面,不需要用户显式的提交作业:
用户代码都是基于RDD的一系列计算操作,实际运行时,这些计算操作是懒执行的,
并不是所有的RDD操作都会触发Spark往Cluster上提交实际作业,
基本上只有一些需要返回数据或者向外部输出的操作才会触发实际计算工作,其它的变换操作基本上只是生成对应的RDD记录依赖关系。
如开始所说,DAGScheduler最重要的任务之一就是 计算作业和任务的依赖关系,制定调度逻辑
DAGScheduler内部维护了各种 task / stage / job之间的映射关系表
TaskScheduler负责调度实际的task任务到executor里,属于物理调度
二、 工作流程
提交并运行一个Job的基本流程,包括以下步骤
划分Stage
当某个操作触发计算,向DAGScheduler提交作业时;
DAGScheduler需要从RDD依赖链最末端的RDD (finalStage) 出发,迭代遍历整个RDD依赖链,进行划分Stage , 并且找到各个Stage之间的依赖关系 。 方法: submitStage()
Stage的划分是以ShuffleDependency为依据的: 方法: getMissingParentStages()
也就是说当某个RDD的运算需要将数据进行Shuffle时,这个包含了Shuffle依赖关系的RDD将被用来作为输入信息源(shuffle write端),构建一个新的Stage ;
这Stage只需要保存shuffleRDD就可以了,stage内其他RDD保存再rdd.dependency里;
由此为依据划分的Stage,可以确保有依赖关系的数据能够按照正确的顺序得到处理和运算。
这个Stage的输出结果的分区数,则由ShuffleDependency中的Partitioner对象来决定。
上一个步骤得到一个或多个有依赖关系的Stage:
生成Job,提交Stage 方法:submitMissingTasks( stage )
其中直接触发Job的RDD所关联的Stage作为FinalStage生成一个Job实例
这两者的关系进一步存储在resultStageToJob映射表中,用于在该Stage全部完成时做一些后续处理,如报告状态,清理Job相关数据等。
具体提交一个Stage时,首先判断该Stage所依赖的父Stage的结果是否可用,如果所有父Stage的结果都可用,则提交该Stage,如果有任何一个父Stage的结果不可用,则迭代尝试提交父Stage。 所有迭代过程中由于所依赖Stage的结果不可用而没有提交成功的Stage都被放到waitingStages列表中等待将来被提交。
Stage 会根据 partition 数来创建对应个数的 task对象 , task又分为 ShuffleMapTask 与 ResultTask :
如果stage是shuffle依赖,每个partition创建一个ShuffleMapTask
如果stage如果不是, 则每个partition创建一个ResultTask , ResultTask 会将计算结果返回到driver端
得到了这个stage要计算的task集合,DAGScheduler会把这些对象封装到 TaskSet 对象里 ,
然后调用 TaskScheduler接口 taskScheduler.submitTasks(TaskSet) 提交给TaskScheduler
什么时候waitingStages中的Stage会被重新提交呢?
每当完成一次DAGScheduler的事件循环以后,会触发一次从等待和失败列表中扫描并提交就绪Stage的调用过程 :
DAGScheduler会检查对应的Stage的所有任务是否都完成了,
如果是都完成了,则DAGScheduler将重新扫描一次waitingStages中的所有Stage,检查他们是否还有任何依赖的Stage没有完成,如果没有就可以提交该Stage。
task调度算法
这个TaskSet最终会触发TaskScheduler构建一个TaskSetManager的实例来管理这个TaskSet的生命周期,而TaskScheduler会在得到计算资源的时候,进一步通过TaskSetManager调度具体的Task到对应的Executor节点上进行运算
而其中的调度算法,再在最下面详解。
发送task到Executor
TaskScheduler 调用 CoarseGrainedSchedulerBackend .reviveOffers()方法
然后 CoarseGrainedSchedulerBackend 发送消息通知 DriverEndpoint , 让它给 CoarseGrainedExecutorBackend ( executorEndpoint ) 发送 LaunchTask 消息 :
因为Executor启动起来后会将自己的资源情况和邮箱地址 ( executorData )反向注册给TaskScheduler
然后TaskScheduler会根据数据本地化级别决定给哪个Executor发送对应的task
然后再将 每个 task先序列化 ,包装成LaunchTask,然后向 executorEndpoint 发送消息
方法: executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
Executor接收task
Executor接收邮件的类为 CoarseGrainedExecutorBackend
它将 task 反序列化, 传给 executor的 launchTask() 方法
该方法会将 task封装成线程 (TaskRunner), 添加到线程池中执行
task任务完成状态的监控
要保证相互依赖的job/stage能够得到顺利的调度执行,DAGScheduler就必然需要监控当前Job / Stage乃至Task的完成情况。这是通过对外(主要是对TaskScheduler)暴露一系列的回调函数来实现的,
对于TaskScheduler来说,这些回调函数主要包括任务的开始结束失败,任务集的失败,DAGScheduler根据这些Task的生命周期信息进一步维护Job和Stage的状态信息。
此外TaskScheduler还可以通过回调函数通知DAGScheduler具体的Executor的生命状态:
如果一个Executor崩溃了或者由于任何原因与Driver失去联系,则对应的Stage的 shuffleMapTask的输出结果也将被标志为不可用。
这也将导致对应Stage状态的变更,再进一步重试失败可能触发 DAGScheduler将对应 Stage的重新提交来 重新计算获取相关的数据。
task任务结果的获取
一个具体的任务在Executor中执行完毕以后,其结果需要以某种形式返回给DAGScheduler,
根据任务类型的不同,任务的结果的返回方式也不同
对于 FinalStage 所对应的任务(对应的类为ResultTask)返回给DAGScheduler的是运算结果本身,
而对于ShuffleMapTask,返回 一个MapStatus对象 给 DAGScheduler 中的 MapOutputTrackerMaster:
MapStatus对象管理了ShuffleMapTask的运算输出结果在BlockManager里的相关存储信息(shuffle write的小文件地址)
而非结果本身,这些存储位置信息将作为下一个Stage的任务的获取输入数据的依据 (reduce task会来申请这个小文件的地址)
对于 ResultTask , 根据任务结果的大小的不同 ,返回的结果又分为两类 :
如果结果足够小,则直接放在 DirectTaskResult 对象内,
如果超过特定尺寸(默认约10MB)则在Executor端会将 DirectTaskResult 先序列化,再把序列化的结果作为一个Block存储在BlockManager里,而后将BlockManager返回的 BlockID 放在 IndirectTaskResult 对象中返回给 TaskScheduler。TaskScheduler可以 调用TaskResultGetter将 IndirectTaskResult 中的 BlockID 取出并通过BlockManager 最终取得对应的DirectTaskResult。
当然从DAGScheduler的角度来说,这些过程对它来说是透明的,它所获得的都是任务的实际运算结果。
没有依赖关系的task如何调度?
TaskSetManager
前面提到DAGScheduler负责将一组任务提交给TaskScheduler以后,这组任务的调度工作对它来说就算完成了,接下来这组任务内部的调度逻辑,则是由TaskSetManager来完成的。
TaskSetManager的主要接口包括:
ResourceOffer :
根据TaskScheduler所提供的 单个Resource资源包括 host,executor 和 locality级别要求 , 返回 一个合适的Task。
TaskSetManager内部会根据 上一个任务成功提交的时间,自动调整自身的Locality匹配策略,如果上一次成功提交任务的时间间隔很长,则降低对Locality的要求(例如从Process Local降低为Node Local),反之则提高对Locality的要求:
即根据 各个Locality级别中TaskSetManager等待分配下一个任务的时间,
如果距离上一次成功分配资源的时间间隔超过对应的参数值,则降低匹配要求(即process -> node -> rack -> any),
而每当成功分配一个任务时,则重置时间间隔,并更新Locality级别为当前成功分配的任务的Locality级别
这一动态调整Locality策略基本可以理解为是为了提高任务在最佳Locality的情况下得到运行的机会,因为Resource资源可能是在短期内分批提供给TaskSetManager的,动态调整Locality门槛有助于改善整体的Locality分布情况。
当然动态Locality也会带来一定的调度延迟,因此如何设置合适的调整策略也是需要针对实际情况来确定的。
handleSuccessfulTask / handleFailedTask /handleTaskGettingResult :
用于更新任务的运行状态,Taskset Manager在这些函数中更新自身维护的任务状态列表等信息,用于剩余的任务的调度。
也会进一步调用DAGScheduler的函数接口将结果通知给它。
TaskSetManager在调度任务时还可能进一步考虑 Speculation (推测执行)的情况:
亦即当某个任务的运行时间超过其它任务的运行完成时间的一个特定比例值时,该任务可能被重复调度。
目的当然是为了防止某个运行中的Task由于某些特殊原因(例如所在节点CPU负载过高,IO带宽被占等等)运行特别缓慢拖延了整个Stage的完成时间。
Speculation同样需要根据集群和作业的实际情况合理配置,否则可能反而降低集群性能以及造成数据重复。
Pool 调度池
TaskScheduler负责将资源提供给TaskSetManager供其作为调度任务的依据。
但是每个SparkContext可能同时存在 多个可同时运行的任务集(没有依赖关系),这些任务集之间如何调度?
由调度池(POOL)对象来决定的,调度池根据调度算法决定哪个TaskSetManager该先执行。
TaskSchedulerImpl在初始化过程中会根据用户设定的SchedulingMode(默认为FIFO)创建一个rootPool根调度池,
之后根据具体的调度模式再进一步创建SchedulableBuilder对象,
具体的SchedulableBuilder对象的BuildPools方法将在rootPool的基础上完成整个Pool的构建工作。
目前的实现有两种调度模式,对应了两种类型的Pool:
FIFO:先进先出型
FIFO Pool直接管理的是TaskSetManager,每个TaskSetManager创建时都存储了其对应的StageID,
FIFO pool最终根据StageID的顺序来调度TaskSetManager
FAIR:公平调度
FAIR Pool管理的对象是下一级的POOL ,子调度池pool 进一步管理属于该调度池的TaskSetManager
公平调度的基本原则是根据所管理的每个Pool中正在运行的任务的数量来判断优先级,用户可以设置minShare最小任务数,weight任务权重来调整对应Pool里的任务集的优先程度。
调度模式配置方式:
默认使用fairscheduler.xml文件,范例参见conf目录下的模板:
<?xmlversionxmlversion="1.0"?>
<allocations>
<pool name="production">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>2</minShare>
</pool>
<pool name="test">
<schedulingMode>FIFO</schedulingMode>
<weight>2</weight>
<minShare>3</minShare>
</pool>
</allocations> Spark应用之间的调度
前面提到调度池只是在SparkContxt内部调度资源,SparkContext之间的调度关系,按照Spark不同的运行模式,就不一定归Spark所管理的了。
在Mesos和YARN模式下,底层资源调度系统的调度策略由Mesos和YARN所决定,
只有在Standalone模式下,Spark Master按照当前cluster资源是否满足等待列表中的Spark应用 对内存和CPU资源的需求,而决定是否创建一个SparkContext对应的Driver,然后放到 waitingDriver数组里,进而完成Spark应用的启动过程,这可以粗略近似的认为是一种粗颗粒度的有条件的FIFO策略吧。