Standalone模式
提交任务的方式
client提交方式

在提交Application的客户端上启动Driver进程
流程: Driver 向 Master 申请资源 ---> Master 在 Worker 启动excutor ---> Driver分发task --->Worker返回结果
总结:
client模式适用于测试调试程序,Driver进程是在提交应用程序的客户端启动的,这样在Driver端可以看到task执行的情况。
生产环境下不能使用client模式,进程提交应用程序,客户端网卡流量暴增的问题。
命令:
./spark-submit --master spark://..... --deploy-mode client --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10
# 或
./spark-submit --master spark://..... --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10 cluster提交方式
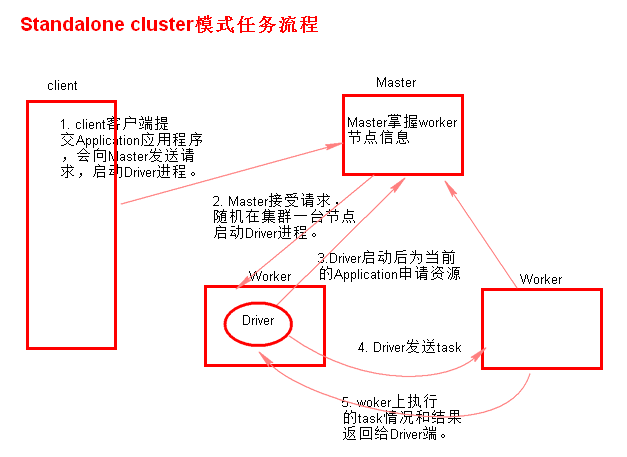
随机选择一台Worker节点启动Driver进程
流程: 向 Master 启动 Driver ---> Master 在某一台启动 Driver ---> Driver 向 Master 申请资源 ---> Master 在 Worker 启动excutor ---> Driver分发task ---> Worker返回结果给Driver
总结:
Driver进程是在集群某一台Worker上启动的,在客户端是无法查看task的执行情况的。
每次Driver会随机在某一台Worker上启动,那么这100次网卡流量暴增的问题就散布在集群上。
命令:
./spark-submit --master spark://..... --deploy-mode cluster --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10 总结以上两种方式提交任务,Driver与集群的通信包括:
1. Driver负责应用程序资源的申请
2. 任务的分发。
3. 结果的回收。
4. 监控task执行情况。
术语解释
Master(standalone):资源管理的主节点(进程)
Cluster Manager:在集群上获取资源的外部服务(例如standalone,Mesos,Yarn )
Worker Node(standalone):资源管理的从节点(进程) 或者说管理本机资源的进程
Application:基于Spark的⽤用户程序,包含了driver程序和运行在集群上的executor程序
Driver Program:用来连接工作进程(Worker)的程序
Executor:是在一个worker进程所管理的节点上为某Application启动的⼀一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应⽤用都有各自独⽴立的executors
Task:被送到某个executor上的工作单元
Job:包含很多任务(Task)的并行计算,可以看做和action对应
Stage:⼀个Job会被拆分很多组任务,每组任务被称为Stage(就像Mapreduce分map task和reduce task一样)
窄依赖和宽依赖
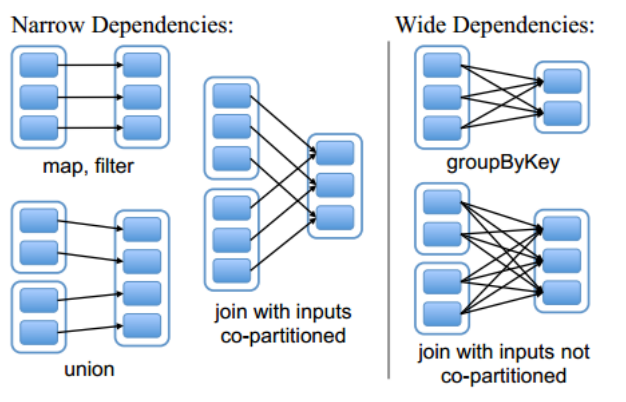
当一个RDD中的一个Partition的数据流向下一个RDD的多个Partition时,这两个RDD为宽依赖 (一对多)
当一个RDD中的一个Partition的数据都只流向下一个RDD的一个Partition时,这两个RDD为窄依赖 (多对一)
当一个RDD中的一个Partition的数据都只流向下一个RDD的一个Partition时,这两个RDD为窄依赖 (多对一)
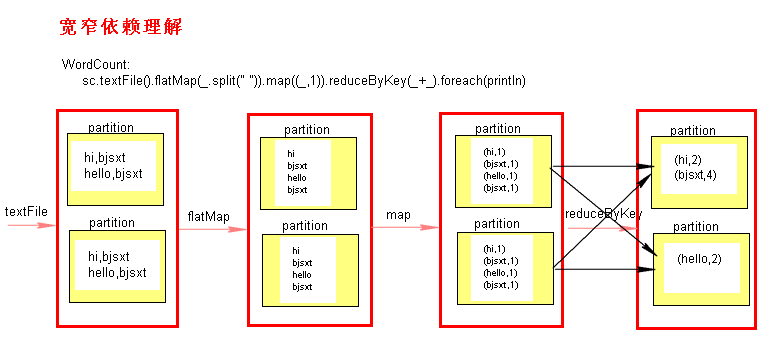
Stage切割规则

当一个 action算子 触发执行Job时,会从 finalRDD往前回溯查找依赖(为什么不从前往后? 因为 RDD 只知道自己依赖谁,不知道被谁依赖)
当碰到 宽依赖 (即碰到会产生shuffle的算子时),就会切分Stage,即 连续的窄依赖 会被划分在同一个Stage
当碰到 宽依赖 (即碰到会产生shuffle的算子时),就会切分Stage,即 连续的窄依赖 会被划分在同一个Stage
Task
在一个Stage内,只有窄依赖,不会产生shuffle ,也就是RDD内的一个Partition数据经过计算后还会在 同一个节点的Partition内 。
也就是说这个Partition的数据可以 只由一个Task来处理,也就是说这些 Task 可以 并行计算。
而由上图可以直观看到 Task 的个数由Stage内的 finalRDD的Partition个数决定 。
pipeline
pipeline
综上可得在一个Stage内,一个Partition会被 一个Task 执行 多个 不会产生Shuffle的算子 进行处理
那么某一个算子的执行结果就不需要落到磁盘,而是每输出一行直接在内存中传递到下一个算子作为输入 。
那么某一个算子的执行结果就不需要落到磁盘,而是每输出一行直接在内存中传递到下一个算子作为输入 。
伪代码(对于一行数据) : map(filter(textFile(path)))
即数据在一个task会像在一个管道(pipeline)内传递,从一个算子传递到另外一个算子,这样提高了执行效率
即数据在一个task会像在一个管道(pipeline)内传递,从一个算子传递到另外一个算子,这样提高了执行效率

也就是Spark中的一个task才相当与MapReduce中的一个task,而不是一个算子相当于MR中的一个task
例如 WordCount:
MapReduce中Mapper做的事情,在Spark中需要map和flatmap两个算子。
而这个两个算子实际运行时并不是独立的,而是通过pipeline管道,flatmap 每输出一行,就会进入到map中执行(而不是flatmap全部执行完,才执行map)
同时由于一个task内算子与算子之间的数据不需要缓存,所以也就解释了为什么checkpoint时,RDD需要重新计算,
而不想重新算一遍的话,就需要在 数据在 pipeline 里流动时,调用执行cache(),让数据落地 而让spark对数据进行缓存。
当 一个task执行完后 ,即到了Stage边界的时候,会 进入 shuffle Write 阶段 ,将 数据落地 到磁盘,等待下一个Stage的task过来拉取聚合 (shuffle read)。
shuffle小文件拉取过程: 详解 shuffle 时的数据拉取过程
shuffle过程详解:Spark Shuffle 详解与优化
运行流程
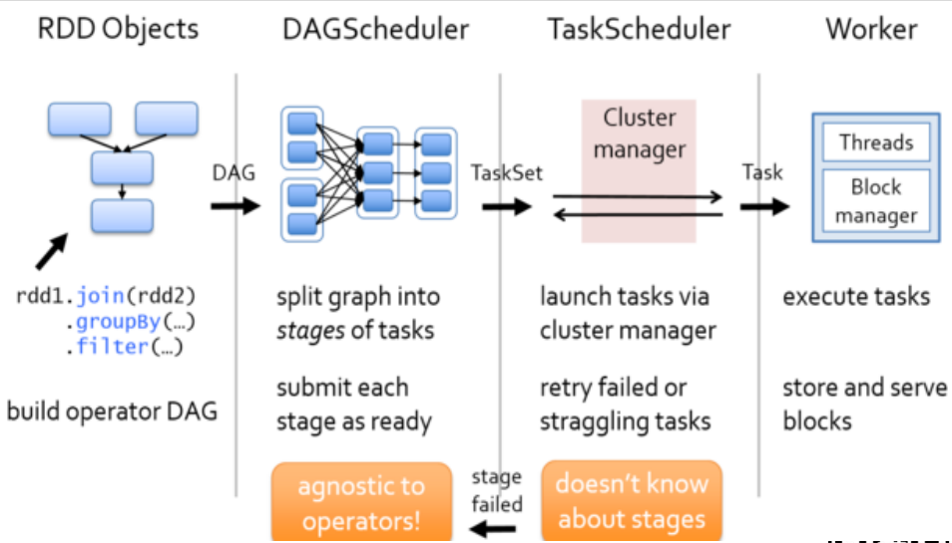
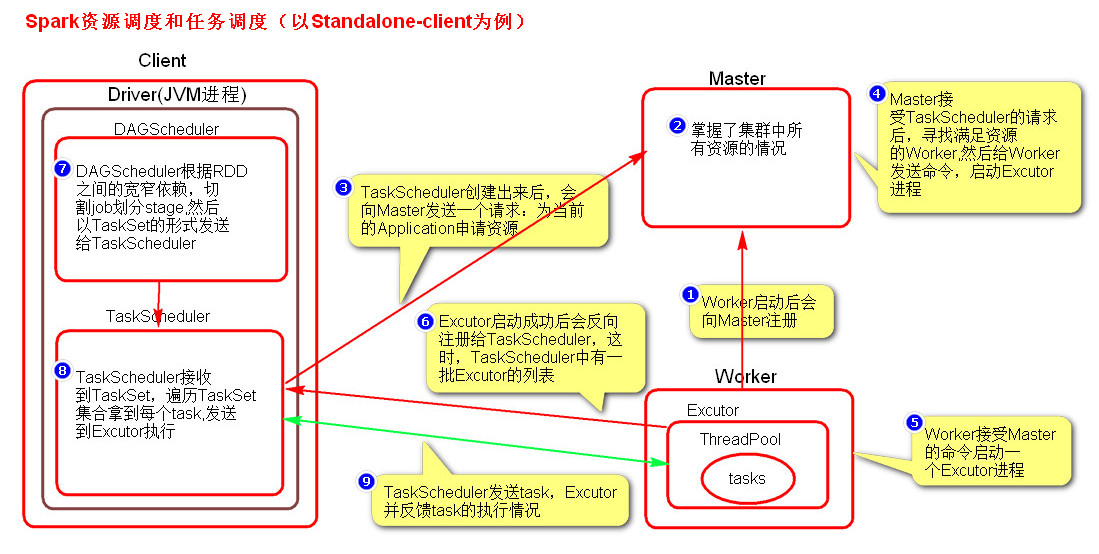
1、当所有Worker启动完成后,Worker会向Master注册,注册信息包括当前节点的资源情况
2、Driver会在代码执行到 new SparkContext() 时启动,根据RDD之间的依赖关系将Application形成一个DAG有向无环图 ,并创建 高层调度器 DAGScheduler 和 任务调度器 TaskScheduler 对象。
3、当TaskScheduler对象创建完后,TaskScheduler会向Master发送请求,注册Application信息,并申请资源。
4、 Master在接收到请求后,根据配置的资源要求决定在哪些Worker上启动多少个Executor , 然后会向Worker发送消息,启动对应的计算进程executor。
5、当Worker上的executor启动成功后会反向注册给 Driver中的 TaskScheduler
6、DAGScheduler会根据action算子划分Job,然后根据 Job 的宽窄依赖来划分 Stage ,并将每个 stage 分为一组并行计算的task,然后将 Stage封装在 taskSet 对象中交给TaskScheduler
7、 TaskScheduler 在收到 taskSet对象后,交给调度池,调度池会将task序列化,然后根据 partition 的数据位置(也就是数据block位置)为优先分发 位置,将task 到对应的 executor中。
8、 executor会执行收到的task,将task反序列化封装成线程,放到线程池中执行,并且会向TaskScheduler发送心跳信息,报告task执行情况。
如果task执行失败,会由TaskScheduler 负责重试,默认重试三次,
如果还是失败,会有 DAGScheduler 重试stage,默认重试4次,
如果还是失败,则 Job失败。
如果开启了推测执行,当TaskScheduler判断某个task为 挣扎的任务(stragglings task 可能失败的任务)时,会另起一个task执行,不会杀死原来的。这时就可能造成数据重复,与消耗了更多的性能资源。
9、 当执行到 sc.stop() 时Driver会向Master发送消息,可以把 executor 全部杀死了。
10、这时Master会通知Worker把excutor给kill掉。
相关源码阅读: Spark 资源调度与任务调度 源码分析
Yarn模式
Spark 运行在 yarn 上,这种模式yarn集群里的机器 不需要 安装Spark,因为 提交节点 执行代码里的主函数时创建的Driver进程 会将Spark依赖包(spark-assembly-1.6.0-hadoop2.6.0.jar 与 application.jar)上传到hdfs,然后执行任务时NodeManager会将依赖包下载到本地,这样Executor就可以执行Jar里的Spark代码了,也就是说有了spark-assembly.jar 这个依赖包就不需要Spark安装包了。
模式配置
client提交方式
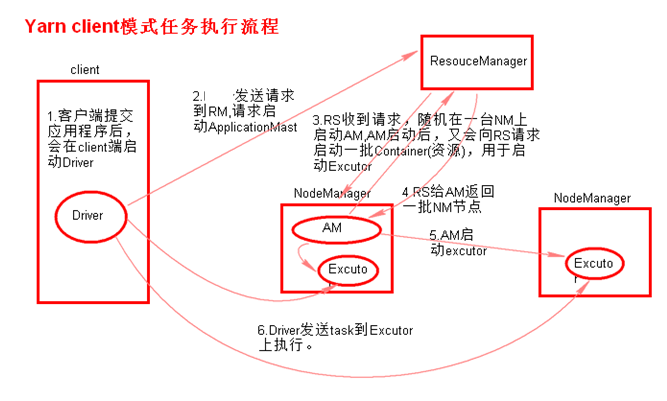
执行流程:
1、在客户端执行提交命令,在本地启动一个Drive进程.
2、Drive进程启动完毕后,会向ResourceManager申请启动一个ApplicationMaster.
3、RM 收到请求,随机选择一台 NodeManager 启动 ApplicationMaster.
4、AM启动后,会向RM请求一批container资源(用于启动Executor).
5、RM会找到一批NM返回给AM,AM会向NM发送命令启动Executor.
6、Executor启动后,会反向注册给Driver,Driver发送task到Executor.
总结
Yarn-client模式同样是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加
ApplicationMaster的作用:
1、为当前的Application申请资源
2、给NodeManager发送消息启动Executor。
注意:ApplicationMaster有launchExcutor和申请资源的功能,并没有作业调度的功能。
命令:
./spark-submit --master yarn-client --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10
# 或
./spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10 cluster提交方式
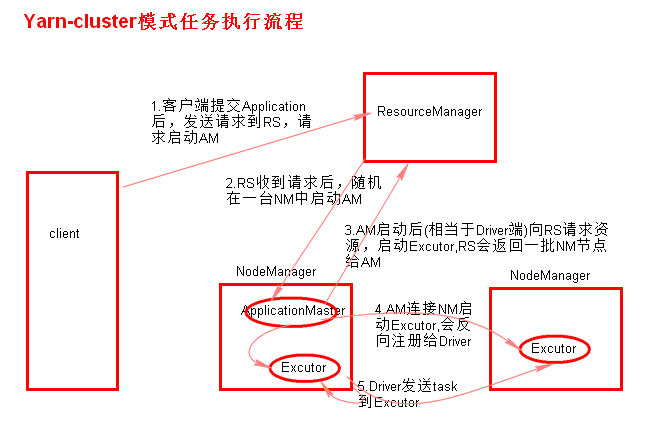
执行流程
1、客户端执行提交命令,并不会启动Drive进程,客户端向RM申请启动一个ApplicationMaster
2、RM收到请求后随机在一台NM上启动AM(相当于Driver端)
ApplicationMaster(Driver)启动成功后向RM申请资源
3、AM启动后,AM发送请求到RM,请求一批container(用于启动Excutor)。
4、RM返回一批NM节点给AM,AM发送请求到NM启动Executor。
5、Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
总结
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
ApplicationMaster的作用:
1、为当前的Application申请资源
2、给NameNode发送消息启动Excutor。
3、任务调度。
命令:
./spark-submit --master yarn-cluster --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10
# 或
./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10粗粒度资源调度:Spark
再Application执行前将 所有的资源申请完毕,然后再进行任务调度,直到所有的 task执行完才释放资源。
资源的复用 : Spark中所有的task可以复用同一批Executor线程资源 ,task执行完后exector不需要杀死
优点:
在每一个task执行前,资源就已经申请完毕了,不需要为每一个task单独去申请资源,那么这task的启动时间就少了,任务会执行更快。
缺点:
不是动态分配资源且task执行完才释放资源,资源无法充分利用
细粒度资源调度:MapReduce
Application在执行之前 不会去提前申请资源,而是直接任务调度,每一task在 执行前自己去申请资源 ,申请到了就执行,申请不到就一直申请。
MapReduce里面每一个map task对应一个JVM进程,每个MapTask执行都要新建一个JVM线程,运行完这个进程就死了。
优点:
可以充分利用集群资源
缺点:
task执行时间加长