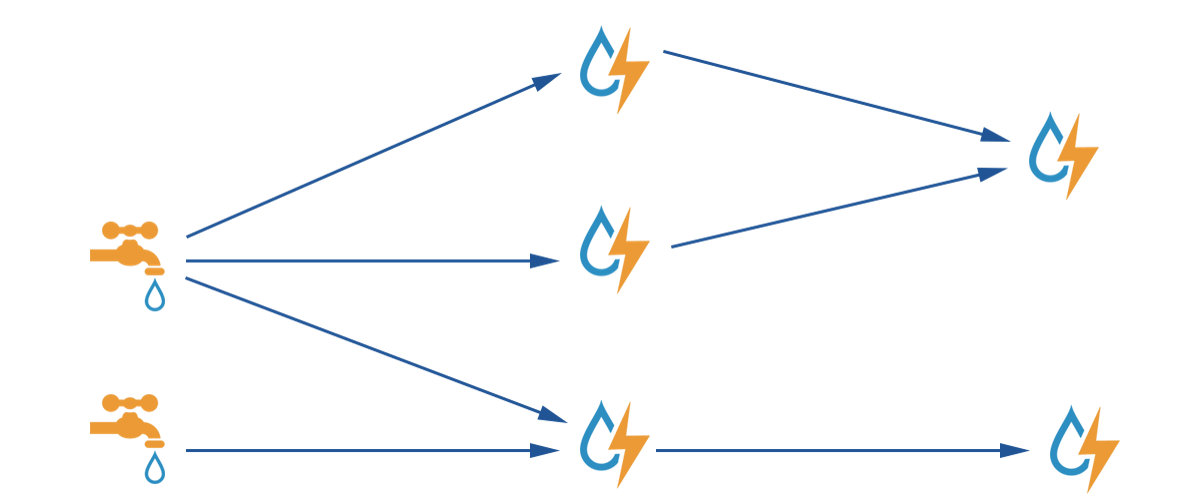
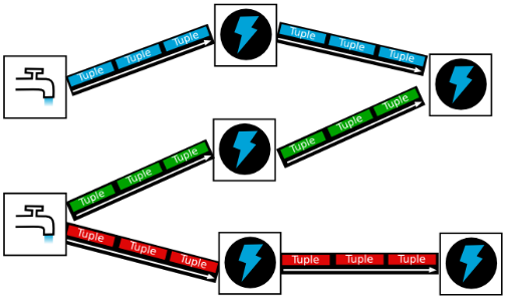
Stream – 数据流
从Spout中源源不断传递数据给Bolt、以及上一个Bolt传递数据给下一个Bolt,所形成的这些数据通道即叫做Stream
Stream声明时需给其指定一个Id(默认为Default)
实际开发场景中,多使用单一数据流,此时不需要单独指定StreamId
Tuple – 元组
Stream中最小数据组成单元
Topology – DAG有向无环图的实现
对于Storm实时计算逻辑的封装
由一系列通过数据流相互关联的Spout、Bolt所组成的拓扑结构
生命周期
此拓扑只要启动就会一直在集群中运行,直到手动将其kill,否则不会终止
(区别于MapReduce当中的Job,MR当中的Job在计算执行完成就会终止)
Spout – 数据源
拓扑中数据流的来源。
一般会从指定外部的数据源读取元组(Tuple)发送到拓扑(Topology)中
一个Spout可以发送 多个 数据流(Stream)
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
Spout中最核心的方法是nextTuple。
该方法会被Storm线程不断调用、主动从数据源拉取数据,再通过emit方法将数据生成元组(Tuple)发送给之后的Bolt计算
Bolt – 数据流处理组件
拓扑中数据处理均由Bolt完成。
对于简单的任务或者数据流转换,单个Bolt可以简单实现;更加复杂场景往往需要多个Bolt分多个步骤完成
一个Bolt可以发送多个数据流(Stream)
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
Bolt中最核心的方法是execute方法。
该方法负责接收到一个元组(Tuple)数据、真正实现核心的业务逻辑
Stream Grouping – 数据流分组
数据分发策略
每一个blot可以有多个实例,这是就要指定数据从 spout或bolt 传递到 下一个blot的哪一个实例 ,指定其中传递的规则
1. Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
轮询,平均分配
2. Fields Grouping
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
3. All Grouping
广播发送,对于每一个tuple,所有的bolts都会收到
4. Global Grouping
全局分组,把tuple分配给task id最低的task 。
5. None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。
6. Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
7. Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
8. customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样。
例子
1、数据累加
Topology
package accu;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.BoltDeclarer;
import backtype.storm.topology.TopologyBuilder;
/**
* Created by Jeffrey.Deng on 2017/9/6.
*/
public class TopologyDemo {
public static void main(String[] args) throws InterruptedException {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new SpoutDemo());
BoltDeclarer bolt = builder.setBolt("bolt", new BoltDemo());
// 指定接受哪个spout数据 , 及spout与bolt的连接方式
bolt.shuffleGrouping("spout");
Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("accu num", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
spout
package accu;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import java.util.List;
import java.util.Map;
/**
* Created by Jeffrey.Deng on 2017/9/6.
*/
public class SpoutDemo extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
List tuple = new Values(1);
collector.emit(tuple);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 定义 输出的 tuple 每一位的 值的名字
// ≈ 列名
declarer.declare(new Fields("num"));
// declarer.declare(new Fields("word", "num"));
}
}
bolt
package accu;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.List;
import java.util.Map;
/**
* Created by Jeffrey.Deng on 2017/9/6.
*/
public class BoltDemo extends BaseRichBolt{
private Map conf;
private TopologyContext context;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
int sum = 0;
@Override
public void execute(Tuple input) {
int i = input.getInteger(0);
sum += i;
List tuple = new Values(sum);
System.out.println("num:" + i + "; sum:" + sum);
collector.emit(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sum"));
}
}
2、WordCount
Topology
package wc;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
/**
* Created by Jeffrey.Deng on 2017/9/6.
*/
public class WcTopology {
public static void main(String[] args) throws InterruptedException {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new WcSpout());
builder.setBolt("bolt1", new WcBolt_One()).shuffleGrouping("spout");
builder.setBolt("bolt2", new WcBolt_Two()).fieldsGrouping("bolt1", new Fields("word"));
Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordcount", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}spout
package wc;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* Created by Jeffrey.Deng on 2017/9/6.
*/
public class WcSpout extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private List<String> list = new ArrayList<String>();
@Override
public void nextTuple() {
list.add("hadoop hive hive zookeeper hbase hive kafka hadoop devin jeffery");
list.add("hadoop hive hive zookeeper hadoop devin jeffery");
list.add("hive kafka hadoop devin jeffery");
for (String s : list) {
collector.emit(new Values(s));
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}bolt1
package wc;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.Map;
/**
* Created by Jeffrey.Deng on 2017/9/6.
*/
public class WcBolt_One extends BaseRichBolt{
private Map conf;
private TopologyContext context;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String[] arr = input.getString(0).split(" ");
for (String s : arr) {
collector.emit(new Values(s, 1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "num"));
}
}bolt2
package wc;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
/**
* Created by Jeffrey.Deng on 2017/9/6.
*/
public class WcBolt_Two extends BaseRichBolt {
private Map conf;
private TopologyContext context;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
private Map<String, Integer> map = new HashMap<>();
@Override
public void execute(Tuple input) {
String word = input.getString(0);
int num = input.getInteger(1);
int count = 1;
if (map.containsKey(word)) {
count = map.get(word) + num;
}
map.put(word, count);
System.out.println("word:" + word + "; count:" + count);
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}